We assert a condition when we believe it to be true in every non-buggy execution of our program, but we want to be notified if this isn’t the case. In contrast, we assume a condition when our belief in its truth is so strong that we don’t care what happens if it is ever false. In other words, while assertions are fundamentally pessimistic, assumptions are optimistic.
C and C++ compilers have a large number of built-in assumptions. For example, they assume that every pointer that is dereferenced refers to valid storage and every signed math operation fails to overflow. In fact, they make one such assumption for each of the hundreds of undefined behaviors in the languages. Assumptions permit the compiler to generate fast code without working too hard on static analysis.
This post explores the idea of a general-purpose assume mechanism. Although this isn’t found (as far as I know — please leave a comment if you know of something) in any commonly-used programming language, it might be useful when we require maximum performance. Although an assume mechanism seems inherently unsafe, we could use it in a safe fashion if we used a formal methods tool to prove that our assumptions hold. The role of the assumption mechanism, then, is to put high-level knowledge about program properties — whether from a human or a formal methods tool — into a form that the compiler can exploit when generating code.
Standard C has the “restrict” type qualifier that lets the compiler assume that the pointed-to object is not aliased by other pointers. Let’s consider this (deliberately silly) function for summing up the elements of an array:
void sum (int *array, int len, int *res)
{
*res = 0;
for (int i=0; i<len; i++) {
*res += array[i];
}
}
The problem that the compiler faces when translating this code is that res might point into the array. Thus, *res has to be updated in every loop iteration. GCC and Clang generate much the same code:
sum: movl $0, (%rdx)
xorl %eax, %eax
.L2: cmpl %eax, %esi
jle .L5
movl (%rdi,%rax,4), %ecx
incq %rax
addl %ecx, (%rdx)
jmp .L2
.L5: ret
Both compilers are able to generate code that is five times faster — using vector instructions — if we change the definition of sum() to permit the compiler to assume that res is not an alias for any part of array:
void sum (int *restrict array, int len, int *restrict res)
Another form of assumption is the __builtin_unreachable() primitive supported by GCC and Clang, which permits the compiler to assume that a particular program point cannot be reached. In principle __builtin_unreachable() is trivial to implement: any unconditionally undefined construct will suffice:
void unreachable_1 (void)
{
int x;
x++;
}
void unreachable_2 (void)
{
1/0;
}
void unreachable_3 (void)
{
int *p = 0;
*p;
}
void unreachable_4 (void)
{
int x = INT_MAX;
x++;
}
void unreachable_5 (void)
{
__builtin_unreachable ();
}
But in practice the compiler’s interpretation of undefined behavior is not sufficiently hostile — bet you never thought I’d say that! — to drive the desired optimizations. Out of the five functions above, only unreachable_5() results in no code at all being generated (not even a return instruction) when a modern version of GCC or Clang is used.
The intended use of __builtin_unreachable() is in situations where the compiler cannot infer that code is dead, for example following a block of inline assembly that has no outgoing control flow. Similarly, if we compile this code we will get a return instruction at the bottom of the function even when x is guaranteed to be in the range 0-2.
int foo (int x)
{
switch (x) {
case 0: return bar(x);
case 1: return baz(x);
case 2: return buz(x);
}
return x; // gotta return something and x is already in a register...
}
If we add a __builtin_unreachable() at the bottom of the function, or in the default part of the switch, then the compiler drops the return instruction. If the assumption is violated, for example by calling foo(7), execution will fall into whatever code happens to be next — undefined behavior at its finest.
But what about the general-purpose assume()? This turns out to be easy to implement:
void assume (int expr)
{
if (!expr) __builtin_unreachable();
}
So assume() is using __builtin_unreachable() to kill off the collection of program paths in which expr fails to be true. The interesting question is: Can our compilers make use of assumptions to generate better code? The results are a bit of a mixed bag. The role of assume() is to generate dataflow facts and, unfortunately, the current crop of compilers can only be trusted to learn very basic kinds of assumptions. Let’s look at some examples.
First, we might find it annoying that integer division in C by a power of 2 cannot be implemented using a single shift instruction. For example, this code:
int div32 (int x)
{
return x/32;
}
Results in this assembly from GCC:
div32: leal 31(%rdi), %eax testl %edi, %edi cmovns %edi, %eax sarl $5, %eax ret
And this from Clang:
div32: movl %edi, %eax sarl $31, %eax shrl $27, %eax addl %edi, %eax sarl $5, %eax ret
The possibility of a negative dividend is causing the ugly code. Assuming that we know that the argument will be non-negative, we try to fix the problem like this:
int div32_nonneg (int x)
{
assume (x >= 0);
return div32 (x);
}
Now GCC nails it:
div32_nonneg: movl %edi, %eax sarl $5, %eax ret
Clang, unfortunately, generates the same code from div32_nonneg() as it does from div32(). Perhaps it lacks the proper value range analysis. I’m using Clang 3.4 and GCC 4.8.2 for this work, by the way. UPDATE: In a comment Chris Lattner provides a link to this known issue in LLVM.
Next we’re going to increment the value of each element of an array:
void inc_array (int *x, int len)
{
int i;
for (i=0; i<len; i++) {
x[i]++;
}
}
The code generated by GCC -O2 is not too bad:
inc_array: testl %esi, %esi jle .L18 subl $1, %esi leaq 4(%rdi,%rsi,4), %rax .L21: addl $1, (%rdi) addq $4, %rdi cmpq %rax, %rdi jne .L21 .L18: rep ret
However, is that test at the beginning really necessary? Aren’t we always going to be incrementing an array of length at least one? If so, let’s try this:
void inc_nonzero_array (int *x, int len)
{
assume (len > 0);
inc_array (x, len);
}
Now the output is cleaner:
inc_nonzero_array: subl $1, %esi leaq 4(%rdi,%rsi,4), %rax .L24: addl $1, (%rdi) addq $4, %rdi cmpq %rax, %rdi jne .L24 rep ret
The preceding example was suggested by Arthur O’Dwyer in a comment on my assertion post.
If you readers have any good examples where non-trivial assumptions result in improved code, I’d be interested to see them.
Next, let’s look at the effect of assumptions in a larger setting. I compiled LLVM/Clang in four different modes. First, in its default “Release+Assertions” configuration. Second, in a “minimal assert” configuration where assert() was defined like this:
#define assert(expr) ((expr) ? static_cast<void>(0) : _Exit(-1))
This simply throws away the verbose failure information. Third, in a “no assert” configuration where assert() was defined like this:
#define assert(expr) (static_cast<void>(0))
Fourth, I turned each assertion in LLVM/Clang into an assumption like this:
#define assert(expr) ((expr) ? static_cast<void>(0) : __builtin_unreachable())
Then I built each of the configurations using GCC 4.8.2 and Clang 3.4, giving a total of eight Clang binaries as a result. Here’s the code size:
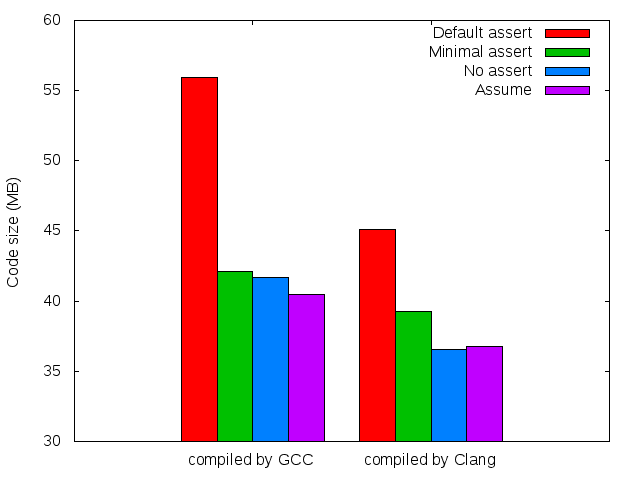
Bear in mind that the y-axis doesn’t start at zero, I wanted to make the differences stand out. As expected, default assertions have a heavy code size penalty. Perhaps interestingly, GCC was able to exploit assumptions to the point where there was a small overall code size win. LLVM did not manage to profit from assumptions. Why would assumptions have a code size penalty over no assertions? My guess is that some assumptions end up making function calls that cannot be optimized away, despite their lack of side effects.
Now let’s look at the performance of the eight clangs. The benchmark here was optimized compilation of a collection of C++ files. Each number in the graph is the median value of 11 reps, but really this precaution was not necessary since there was very little variance between reps. Note again that the y-axis doesn’t start at zero.
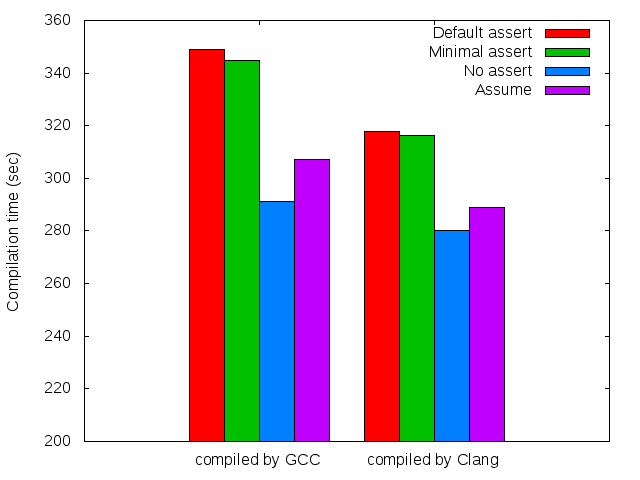
Both compilers are slowed down by assumes. Again, I would guess this is because sometimes the compiler cannot elide function calls that are made during the computation of a expression that is being assumed.
One surprise from these graphs is that Clang is generating code that is both smaller and faster than GCC’s. My view (formed several years ago) has been that Clang usually produces slightly slower code, but requires less compile time to do it. This view could easily have become invalidated by rapid progress in the compiler. On the other hand, since the code being compiled is LLVM/Clang itself, perhaps we should expect that Clang has been extensively tuned to generate good object code in this case.
A not-surprise from these graphs is that we generally cannot just take a big collection of assertions, turn them into assumptions, and expect good results. Getting good results has two parts: an easy one and a hard one. The easy part is selectively removing assumptions that are hurting more than they help. These would tend to be complex conditions that are slow to compute and that have no chance of generating dataflow facts that the compiler can make use of. This picking and choosing could even be done automatically.
The second part of getting good results out of assumptions is creating compilers that are more generally capable of learning and exploiting arbitrary new dataflow facts provided by users. In the short run, this is a matter of testing and fixing and tuning things up. In the long run, my belief is that compilers are unnecessarily hampered by performance constraints — they have to be pretty fast, even when compiling large codes. An alternative is to support a “-Osearch” mode where the compiler spends perhaps a lot of time looking for better code sequences; see this comment from bcs. The compiler’s search could be randomized or it could involve integration with an SMT solver. Companies that burn a lot of CPU cycles in server farms should be highly motivated to optimize, for example, the 500 functions that use the most power every day. I’m assuming that some sort of systematic cluster-wide profiling facility exists, we don’t want to waste time optimizing code unless it’s causing pain.
The postcondition of any assumption is the same as the postcondition of asserting the same expression. Thus, we can see that asserts can also make our code faster — but this requires the speedup from the extra dataflow facts to outweigh the slowdown from the assertion check. I don’t know that anyone has ever looked into the issue of when and where assertions lead to faster code. We would not expect this to happen too often, but it would be cute if compiling some big program with -DNDEBUG made it slower.
Although they would normally be used to support optimization, I believe that assumptions can also directly support bug detection. A tool such as Stack could be modified to analyze a program with the goal of finding code that becomes dead due to an assumption. The presence of such code is likely to signal a bug.
In summary, assume() is a mechanism for introducing new undefined behaviors into programs that we write. Although this mechanism would be easy to misuse, there’s no reason why it cannot be used safely and effectively when backed up by good programming practices and formal methods.
21 responses to “Assertions Are Pessimistic, Assumptions Are Optimistic”
The ARM commercial compiler has an __assume() directive like what you describe. Most DSP compilers also have pragmas or other directives by which the programmer can provide guarantees about things like number of loop iterations without the overhead of a traditional assert().
A couple of years ago, I did some investigation into the effects of using __built-in_unreachable() in this way on some audio/video codecs. Unfortunately it uncovered enough bugs (since fixed) in gcc that I gave up the effort.
Interesting to see how much faster “minimal assert” is than the normal “Release+Assert” mode. Perhaps Clang should make that the default, since anyone who isn’t a compiler developer won’t learn much from the assertion stack trace.
Does LLVM have a way to assume something without bothering to compute it at runtime, even if Clang doesn’t expose it?
It’s a known deficiency of the LLVM optimizer that we don’t do optimizations based on these sorts of assumptions. If you’re interested, it is tracked by:
Make better use of conditional unreachable’s in LLVM
http://llvm.org/bugs/show_bug.cgi?id=810
As you say, it is a delicate dance, because the assertion condition could be non-trivial, have side effects, etc, and the optimizer won’t be able to throw that away if you rework the ‘assert’ macro to unconditionally do this.
MSVC already has an __assume intrinsic:
http://msdn.microsoft.com/en-us/library/1b3fsfxw
http://blogs.msdn.com/b/freik/archive/2006/01/30/519814.aspx
Thanks Mans and igorsk, great to see this is relatively common.
Chris, thanks for the link, lots of good reading there!
Jesse, as far as I know, __builtin_unreachable() and the noreturn function attribute are all we get in LLVM.
I think you could automatically elide expensive-and-useless-for-optimization tests from assume() while still allowing them to be seen by assert() by placing such tests into functions marked with the “pure” function attribute.
kme– that’s probably a better idea that the one I had, which is to just search for the set of assumptions that results in the smallest or fastest code. But anyhow, my idea is already running. Will report results presently.
“Bear in mind that the y-axis doesn’t start at zero, I wanted to make the differences stand out.”
Just don’t do that, not even if you fess up to it. Give the numbers in a table, we’re presumably all numerate here. Go crazy with highlighting if you must. You could also pick a baseline (like “no assert”) if you want to emphasize the differences. Now it just isn’t possible to see, at a glance, what the magnitude of the differences really is, even though that’s what the graph is supposed to do. “Look it’s bigger!” is a waste of pixels.
Sorry, this is a pet peeve 🙂 I don’t mean to distract from the main topic.
Actually, Jeroen Mostert is very right. It should start at 0, or put numbers up, with percentages. Presenting information is a serious, important topic, worth the time and effort. I suggest reading “The Visual Display of Quantitative Information”. There, Tufte will tell you quite plainly that starting that graph at anywhere other than 0 is very-very misleading — as it mislead me, btw. He will also complain about bar charts, and for a good reason. It’s really worth the read.
The idea I love, btw. I work on formal methods and the systems at the heart of symbolic execution systems. I think there is plenty of space to optimize compilers with automated reasoning/solving systems. Last time I raised the issue on the GCC mailing list (http://gcc.gnu.org/ml/gcc-help/2011-04/msg00246.html), I got a reply that using symbolic systems to prove certain facts and exploiting them to speed up the code would take too much compile-time, and they would rather use the same system to do more optimal register allocation. Then… someone wrote a register allocator based on an commercial solver(CPLEX): http://www.anrg.it.usyd.edu.au/~scholz/publications/jmlc06b.pd It’s getting there, only proof-of-concept, but still.
Hi Mate, I have read the Tufte books, and quite liked them. I guess I just didn’t listen to all of his advice.
Fixed link:
http://sydney.edu.au/engineering/it/~scholz/publications/jmlc06b.pdf
It looks like nice work. One reason that I really think solvers are the future of compilation is that solvers — unlike compilers — can explain their reasoning, if asked. So getting proof witnesses is dramatically simplified.
There’s a second (quite) minor benefit here — more code with “performance” assumes would slightly improve the chances of applying model checkers and other verification tools effectively at low cost. Adding all the required “no, don’t tell me it fails if x is negative, you idiot” assumes is one manual labor cost of many of these tools. Making it as standard an idiom as assert (if much less used) would also help standardize tool input forms, at least for C, something Martin Erwig and I argued for in a WODA 2012 paper on assert/assume/choose.
John, based on Mans, do you think throwing in (guaranteed to hold) assumes in Csmith output could expose interesting bugs, or would those tend to be bugs nobody cares about?
Alex I think that bugs in __builtin_unreachable() would be highly interesting to compiler developers. Csmith is already capable of generating assertions, so assumptions are trivial. I’ll give it a try if I can make a bit of time.
Bit of topic, but i think You should use the lowest running time instead of median. After all measurement errors in this case are only positive (compilation can only be slowed down for example by disc access or whatever).
Does information like probably (boolean value is probably true, like 90+% of time) rather than assume (100% of time) would be of any use to optimizers?
Oh, wait, i guess for example memory access can be also “faster than usual”, so maybe median is not a bad idea.
Hi RadosÅ‚aw, if using some sort of low-level timer like RDTSC on a uniprocessor, I’d probably go ahead and take the minimum value. Using a high-level timer on a multicore I don’t necessarily trust the timing code and cross-processor clock synchronization so median seems better.
Yes, information about unlikely branches is very useful to optimizers. This kind of thing was crucial in reducing the overhead of our undefined behavior checking for Clang, for example.
@reghehr “It looks like nice work. One reason that I really think solvers are the future of compilation is that solvers — unlike compilers — can explain their reasoning, if asked. So getting proof witnesses is dramatically simplified.”
Actually, the only 2 proof logging format that SAT solvers can use right now, RUP and DRUP (the better one), are both really verbose and difficult to check. Also, until recently basically no solver could log either, but luckily the last SAT competition made it mandatory, so it’s pretty OK now. DRUP needs to be compressed, and even then checking it takes much longer than actually creating it. The checker written is also not very efficient to say the least — though it has to be correct, so maybe that’s an OK trade-off.
For higher-level languages (think SMT like STP, and symbolic execution like KLEE) there is absolutely no proof logging & checking at all. Also, fuzz-testing on higher-level languages like SMT is harder (much more complex input language) and I’m sure there are lots of bugs hidden there.
A while back, I took a look at improving LLVM’s ability to handle assumes. I was interested in a particular use case: pre and post conditions, in particular class invariants.
These have a fairly standard form of:
assume(x);
..do something
assert(x);
I found at the time that LLVM would happily throw away the assume block, but would not touch the assert block. The reason was that unreachability information was being exploited too early in the compiler and then was being thrown away before it reached later passes.
As a complete utter hack, I created a wrapper around __builtin_unreachable, optimized the code once, desugared the wrapper, and then optimized again. This gave the desired result for many cases.
In effect, my hack was a messy solution to a pass ordering problem. By running the optimizer the first time, the two conditions are commoned (CSE) and the unreachable information could remove both dead code paths.
You can find the code for this here: https://github.com/preames/llvm-assume-hack.
Keep in mind that all of this was done a while ago and might not properly reflect the current state of LLVM.
Another interesting hack might be writting a pass which unconditionally removes values which only flow into assume checks. This would address (in a very hacky form) the issue of function calls remaining in the final IR. (I haven’t implemented this one, but doing so would be fairly quick.)
I’d be really curious to see what your results looked like with one or both of those hacks in place.
Philip, thanks! I’m running some experiments right now on the performance effects of assertions with the idea that the same infrastructure can be used to measure assumes. I had been planning not to measure LLVM due to Chris’s comment but I’ll see about applying your hack. Perhaps if I can publicize some good results this will motivate people to get this fixed for real.
@regehr – Send me an email and let’s chat. I’ve been playing with the topics around assert and assume performance for a while. If nothing else, I’d love to see your results.
Given I’ve moved into actually working with LLVM as my day job rather than just playing around, I might even be able to help with some of the upstram work.
I know there are a number of folks working on somewhat related topics. I think folks are mostly leaning towards using a metadata representation rather than arbitrary code expressions though. Not a huge fan of that personally, but we’ll see where it leads.
p.e. If anyone is interested, my earlier comment became a slightly longer blog post. http://www.philipreames.com/Blog/2014/02/15/tweaking-llvm-to-exploit-assumex/ For those who’ve already read my comment above, the only real change was acknoledging just how unsound my second proposed hack was.