As a consequence of my last post, I spent some time on the phone Friday with Andy Chou, Coverity’s CTO and former member of Dawson Engler’s research group at Stanford, from which Coverity spun off over a decade ago. Andy confirmed that Coverity does not spot the heartbleed flaw and said that it remained stubborn even when they tweaked various analysis settings. Basically, the control flow and data flow between the socket read() from which the bad data originates and the eventual bad memcpy() is just too complicated.
Let’s be clear: it is trivial to create a static analyzer that runs fast and flags heartbleed. I can accomplish this, for example, by flagging a taint error in every line of code that is analyzed. The task that is truly difficult is to create a static analysis tool that is performant and that has a high signal to noise ratio for a broad range of analyzed programs. This is the design point that Coverity is aiming for, and while it is an excellent tool there is obviously no general-purpose silver bullet: halting problem arguments guarantee the non-existence of static analysis tools that can reliably and automatically detect even simple kinds of bugs such as divide by zero. In practice, it’s not halting problem stuff that stops analyzers but rather code that has a lot of indirection and a lot of data-dependent control flow. If you want to make a program that is robustly resistant to static analysis, implement some kind of interpreter.
Anyhow, Andy did not call me to admit defeat. Rather, he wanted to show off a new analysis that he and his engineers prototyped over the last couple of days. Their insight is that we might want to consider byte-swap operations to be sources of tainted data. Why? Because there is usually no good reason to call ntohs() or a similar function on a data item unless it came from the network or from some other outside source. This is one of those ideas that is simple, sensible, and obvious — in retrospect. Analyzing a vulnerable OpenSSL using this new technique gives this result for the heartbleed code:
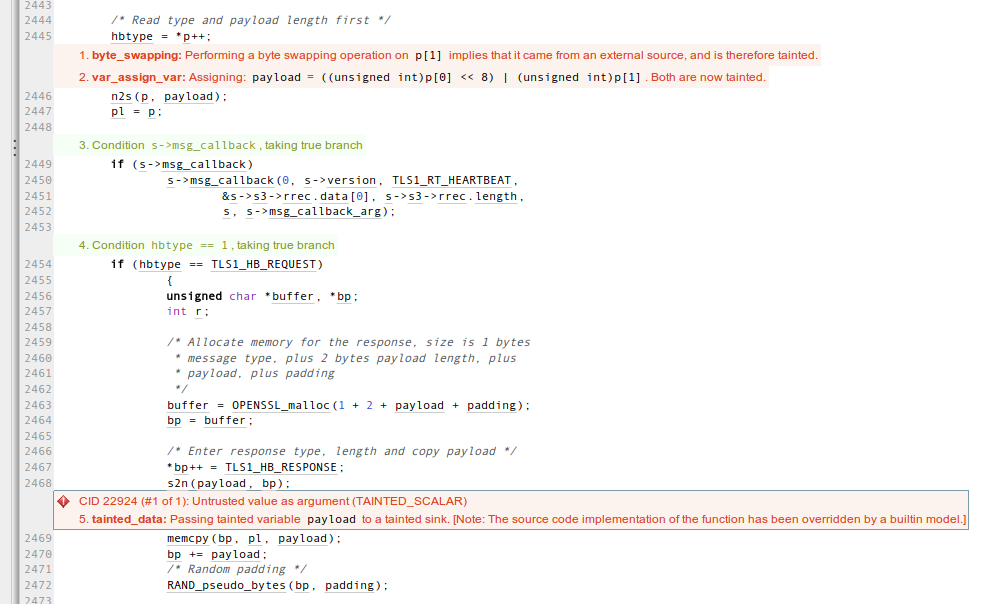
Nice! As you might guess, additional locations in OpenSSL are also flagged by this analysis, but it isn’t my place to share those here.
What issues are left? Well, for one thing it may not be trivial to reliably recognize byte-swapping code; for example, some people may use operations on a char array instead of shift-and-mask. A trickier issue is reliably determining when untrusted data items should be untainted: do they need to be tested against both a lower and upper bound, or just an upper bound? What if they are tested against a really large bound? Does every bit-masking operation untaint? Etc. The Coverity people will need to work out these and other issues, such as the effect of this analysis on the overall false alarm rate. In case this hasn’t been clear, the analysis that Andy showed me is a proof-of-concept prototype and he doesn’t know when it will make it into the production system.
UPDATE: Also see Andy’s post at the Coverity blog.
17 responses to “A New Development for Coverity and Heartbleed”
Byte swapping does not necessarily imply the data comes from an external source. For example, when writing graphics code, you sometimes need to do byte swapping if you’re converting between 24-bit RGB and BGR image formats (Windows’ GDI famously uses BGR so this is one place where you need to do such conversions). Yes, this can be done using arrays, but sometimes byte swapping is used.
Thanks for the analysis.
What if you’re preparing data for transmission over a network?
Interesting approach! Kudos to Coverity for jumping on it so quickly.
Taint analysis is notoriously prone to false positives; as well as the reasons you list, there are many situations where relations between variables mean that tainted data doesn’t cause problems. [For example, the size of the memcpy target (bp) is known to be greater than payload; so even though payload is tainted, there isn’t a risk of a write overrun.] But even noisy warnings can be very useful — when we first implemented simple taint analysis in PREfix a decade ago, the first run was 99% false positives but one of the real bugs we found was in a system-level crypto module. So with the increased attention to these kinds of bugs after Heartbleed, seems like a great time for more attention to these classes of bugs.
So you found out about this on Friday evening and are publishing it on Saturday? Did the OpenSSL team confirm that the “other locations” are harmless in that brief time period? I sure hope so.
There is no harm, in general, in identifying too many tainted sources. An extraneous taint source is only a problem if it also appears to flow into a real (or extraneous) taintedness sink. In both @buggy’s and @what’s cases it seems unlikely that the post-swapped values will flow into a taintedness sink. But only trying the heuristic on lots of real world code will tell with these kinds of things.
This reflects the exact situation on how current production static analyzers handle difficult security bugs: customizing the analyzer for targeted bugs. A better way is to come yet.
Of course, you need to be building a version that requires the byte swapping. If you are compiling for a big-endian machine, this typically does not need to be done. So, if the static analyser is working on post-macro expansion level, this would be missed on big-endian machines. It’s a pretty obvious hint if you are just reading the source code for fun and jollies. We knew about this trick at Microsoft over 15 years ago.
Of course this analysis is far from perfect, but a good principle is that when you discover a bug you should look for other similar bugs – and in the context of the OpenSSL codebase, this analysis obviously works for that purpose. I wonder how easy it is to add your own rules to tools like Coverity when you find some class of bug that you want to look for more incidents of.
As an example I found a problem where a programmer had used memset(this, 0, sizeof(*this)) in a constructor — that worked until someone added a member that had a vtable. I also found another case of implementing operator== using memcmp(this, that, sizeof(*this)) — that worked until a member was added which received padding. Finally I did a search for all mem.*(this strings in the code and fixed the rest of the problems. If we were using a static analyser I would want to add patterns for those problems (if they were not already there) so nobody could re-introduce that kind of problem without it getting flagged.
Hi Stephen, the OpenSSL team has not confirmed anything. My judgement is that an informal description of a detector for a class of errors, and a remark that it works, does not constitute irresponsible disclosure of vulnerabilities.
Or to say the same thing a different way: I believe that the kind of people who can take what I’ve written here and turn it into a vulnerability (if indeed there is another one) would be perfectly capable of finding that vulnerability without the information here.
I think there is room for 4 classes of static analyzers from the quadrants of the fast/low-noise vs. slow/high-noise axis and the sound vs. un-sound axis.
Fast and sound is effectively what is built into compilers. Fast and unsound is lint, more aggressive warnings etc. The slow classes are what has been discussed recently here.
The actionable thoughts are first that it would be nice to have a tool that can do all four classes (LLVM?) and second that something like OpenSSL should pass cleanly on all of them, even if it required changing its architecture to do so.
If there was such a set of tools in the open source community, I’d like to see them develop a culture or doing postmortem reports on major bugs in open source projects WRT how well the tools did at finding the bug and, if it doesn’t, make an effort to create an as general and useful as practical pass to pick it up (which may or may not get added).
Perhaps look for data sourced from things like read() system calls and mapped memory addresses/DMA instead, excluding things inside the process image like strings? The contents of these memory buffers should likely be treated as untrusted since they originate from hardware, files, network I/O or untrusted shared memory IPC with other processes or even the kernel. What would the SNR look like then?
I think a key insight here is how critical/powerful the “policy” (in this case, taint source) for the static analysis technique (in this case taint analysis) is. I fear that way too often papers are written only about techniques. I can’t recall a single paper going through the different possible policies or innovating on policies only (I don’t want a new technique in such a paper).
Common cryptographic functions such as SHA256 perform byte-swap operations on little-endian machines as part of pre and post processing of data.
optimiz3, I was worried about that as well, but this effect does not seem to be causing a lot of false alarms in OpenSSL. Perhaps it is uncommon for data that is byte-swapped by SHA256 to find its way to a sensitive sink.
Wouldn’t it be more useful if security-critical software like OpenSSL used some special “tainting markers” right in the code, instead of building a separate tool that treats OpenSSL as “opaque” code and tries to make sense of it? I mean, the analysed code could actually cooperate with the static code analyser, by having the OpenSSL devs adding hints to the source code like “every argument in this function must be untainted”, or “the return values of this function are all tainted”. Wouldn’t that approach be more realistic, more deterministic and hence also easier to understand by other developers?
Thanks for the analysis. This proves that there is a rigorous need for further inspection into the code as more flaws may appear