[I don’t seem to be getting blog entries written lately. The semester has turned out to be surprisingly busy and, also, I’m working on a few longer pieces that have ended up being harder to write than I’d hoped. Anyhow, the piece below isn’t the sort of thing I usually post, you can think of it as sort of a guest post. The context is the recent Bash bug which — unlike Heartbleed — completely failed to stir up a pile of “here’s how to find it using static analysis” posts, for reasons that Pascal explains very nicely.]
A3 Mitigation of Shellshock Vulnerability
Aaron Paulos, Brett Benyo, Partha Pal, Shane Clark, Rick Schantz (Raytheon BBN Technologies)
Eric Eide, Mike Hibler, David Johnson, John Regehr (University of Utah)
[Distribution Statement “A” (Approved for Public Release, Distribution Unlimited)]
Summary:
The shellshock/Bash bug has been in the news a lot recently and it seemed like a great opportunity for us to test our A3 fully automated repair technology against a real zero-day attack. We found that the mandatory mediation policy enforced by A3 blocked the effect of the injected command attack. The policy violation triggered A3 to automatically explore and repair the underlying security hole. A3 took around 2 minutes to automatically find a repair using virtual machine introspection to insert a system call block, preventing a sys_clone call made by Bash, and an additional 1.5 minutes to find a source code repair in the Bash code. The A3 shellshock experiment is an example that illustrates the recent progress made by the survivability and resiliency research community to automate post-incident response management and to reduce the time to patch.
Details:
We have been developing the A3 (Advanced Adaptive Applications) Environment for the past four years as part of the DARPA Clean-slate design of Resilient, Adaptive, Secure Hosts (CRASH) program. A3 aims to make network facing services and applications resilient against zero-day attacks through the use of containerization, mandatory I/O mediation, execution introspection, and defensive adaptation. Recently, our focus has been on automatically reasoning about attack manifestations and dynamically producing new network filters, system call policies, and even source patches to mitigate the underlying vulnerability. A3’s adaptive experimentation utilizes record and replay, machine learning algorithms, and execution tracing across the OS and application boundaries.
For the shellshock experiment, we applied A3 to a simple app store web application built on a standard LAMP stack with a vulnerable Bash version. It took us a few hours to get the source, build environment, and regression tests for Bash 4.2 into the “laboratory” area of the A3 environment (i.e., a set up for in-situ and online testing of new security adaptations of the protected application). This was only necessary to generate a source code level repair; generating the system call block repair did not require any code, build environment, or regression tests.
Constructing an attack to exploit the vulnerability was trivial. We simply inserted an exploit that attempted to cat a “passwd” file into a GET request:
GET /appstore/index.php HTTP/1.1
User-Agent: () { :;}; /bin/cat /home/mitll/passwd > /tmp/hello.txt
Host: 155.98.38.76:7701
Accept: */*
This style of attack was chosen because it mimicked what hackers attempted during a capture the flag experiment. We launched the attack, and watched A3 work.
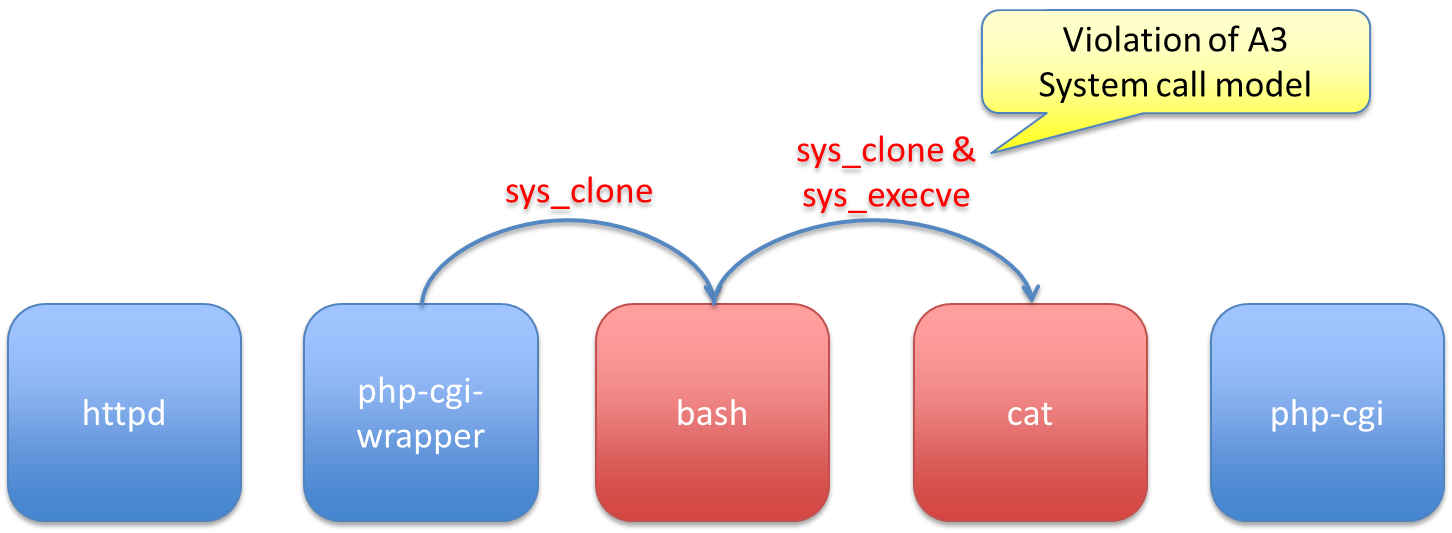
First, A3’s mandatory mediation blocked the attack because the attack was trying to access a directory that is not allowed by the mediation policy of the protected application. It is not guaranteed that all attacks will be stopped there, of course — mediation policies are not guaranteed to be perfect, and the attack may involve operations that are permitted but cause an undesired effect at a later stage. However, the unauthorized access attempt triggered A3’s automated repair process, much like a later-stage undesired condition would. A3 took ~2 minutes to find a repair using virtual machine introspection to block a sys_clone call made by Bash. This was accomplished by replaying the attack within A3 (i.e., in the “laboratory” area), running a full system call analysis, and testing system call block policies for any unique calls or call parameters found. A3 took an additional ~1.5 minutes to find a source code repair in the Bash code by analyzing the call stack when the sys_clone call was attempted. Below are the call stack and a slightly more readable figure for our particular attack payload:
#0 0x00007f17a8f5f936 in __libc_fork () at ../nptl/sysdeps/unix/sysv/linux/x86_64/../fork.c:131
#1 0x0000000000448ebe in make_child (command=0xc7eb08 "/bin/cat /home/mitll/passwd > /tmp/hello.txt", async_p=0) at jobs
.c:1738
#2 0x000000000043a271 in execute_disk_command (words=0xc7a688, redirects=0xc7e688, command_line=0xc7ea48 "/bin/cat /home
/mitll/passwd > /tmp/hello.txt", pipe_in=-1, pipe_out=-1, async=0, fds_to_close=0xc7a4c8, cmdflags=0) at execute_cmd.c:46
70
#3 0x0000000000438fd0 in execute_simple_command (simple_command=0xc7e648, pipe_in=-1, pipe_out=-1, async=0, fds_to_close
=0xc7a4c8) at execute_cmd.c:3977
#4 0x0000000000433179 in execute_command_internal (command=0xc7e608, asynchronous=0, pipe_in=-1, pipe_out=-1, fds_to_clo
se=0xc7a4c8) at execute_cmd.c:735
#5 0x0000000000435d26 in execute_connection (command=0xc7e708, asynchronous=0, pipe_in=-1, pipe_out=-1, fds_to_close=0xc
7a4c8) at execute_cmd.c:2319
#6 0x00000000004334d4 in execute_command_internal (command=0xc7e708, asynchronous=0, pipe_in=-1, pipe_out=-1, fds_to_clo
se=0xc7a4c8) at execute_cmd.c:891
#7 0x0000000000487ee3 in parse_and_execute (string=0xc7dc08 "HTTP_USER_AGENT () { :;}; /bin/cat /home/mitll/passwd > /tm
p/hello.txt", from_file=0x7fff289f6c4e "HTTP_USER_AGENT", flags=5) at evalstring.c:319
#8 0x000000000043af8c in initialize_shell_variables (env=0x7fff289f50e0, privmode=0) at variables.c:350
#9 0x000000000041de8f in shell_initialize () at shell.c:1709
Looking for a place to stop the manifestation, A3 developed the following patch at line 3979 in execute_cmd.c, which just unconditionally skips the function call leading directly to our observed attack. This repair does not fix the Bash parser, but instead disables functionality that is unnecessary for processing legitimate requests by the protected application (app store running on the LAMP stack).
if (0) {
result = execute_disk_command ( words, simple_command->redirects,
command_line, pipe_in, pipe_out,
async, fds_to_close,
simple_command->flags);
}
For this experiment we started with a single malicious request sent to the application and A3 used benign traffic and a subset of the tests shipped with Bash to reason about and develop its patch. We are not claiming that the A3-derived code repair is the right fix (although it is fairly close to the location of the proposed fix). With a little more time and tweaking (e.g., additional attack attempts trying to cause different manifestations, regression tests), we can refine it further.
What we are claiming is that A3 was able to automatically localize and find a patch that makes the protected application (our LAMP exemplar) resilient in seconds. If the adversary tries another exploit and causes an undesired condition in the protected application, A3 will find a refinement. A3’s explanation also provides a wealth of localization and causal relation information along with the patch by outputting the malicious message and the full call stack. This can be extremely helpful for a human developer trying to address the problem.
Vulnerabilities and attacks relying on arcane parsing bugs or obscure protocol features seem to get all the attention these days. However, progress is being made in faster, more efficient and more effective ways to deal with these thorny issues as well. The ability to block attack manifestations, and deliver useful debugging/forensic information along with repair candidates in the form of code patches has great potential to mitigate some of the major issues faced with network-facing software today, including the large average lifespan of zero-day vulnerabilities, difficulty in pinpointing vulnerable code, patch validation, and time and level of expertise needed to keep ubiquitous services and infrastructure like OpenSSL and Bash safe.
Further Information:
If you are interested in learning more about the A3 project, we have a list of published papers available at the project page. For more details on the repair technology, we are working on a paper that includes more technical details and experiments run with other bugs. For information about the CRASH program, contact the DARPA Public Affairs office at outreach@darpa.mil.
13 responses to “Fun with Shellshock”
This is great work. Though I must confess I’m more interested (and far more uneasy) about the other side of the coin — people developing projects like these involving machine learning to find and exploit the vulnerabilities in a fully automated fashion. This is related to, but not quite the same as, attempts at verification — the exploit doesn’t need to care about how it works or how to fix it — and I have a feeling research in this area doesn’t always see the light of day, for obvious reasons…
Let me add that A3’s powerful virtual-machine introspection (VMI) tool is open source and available for download.
It’s called Stackdb, and it is available here: https://gitlab.flux.utah.edu/a3/vmi.
Stackdb is described in a paper published at the VEE ’14 conference. That paper is available here.
For sufficiently circumscribed deployments and with through enough tests, it seems to me you should be able to “delete” all code that your tests harness fails to exercise.
@bcs: Yes, the quality of the repair depends a lot on the quality of the test suite.
Let me mention, though, that the test suite does not need to be entirely handmade. For instance, if you have a bunch of recently recorded “benign” inputs, one can use those and check that the observed behavior is the same before and after the program modification. This technique is probably more applicable to stateless servers than it is to stateful shells, but you get my main point—there are often many sources of useful test inputs.
I was taking good tests as a given and considering what could be done to reduce the attack surface at (or before) compile time without first needing a known exploit.
Hi bcs, I think it goes without saying that before deploying a technique like this for real, you’d want a REALLY good test suite, at which point I agree: uncovered code becomes irrelevant/harmful and should be deleted.
By “deleted” I hope you mean “replaced with a call to abort()”.
Yes, good point Jesse.
re: about().
That very much depends. In a classic CGI fork-per-query set up, sure, maybe (but you might not if you can figure out how to make the build tool that’s doing the stripping automatically find a “safe” alternative like the shell-shock example does).
If you are using a non-forking server, than pointing assumed-dead-code at abort() just turns an exploit of unknown harm into a DOS vector of known harm.
bcs: If you don’t abort(), then you risk removing error-handling code and consequently introducing a new security bug.
If you hit a code path that was dead in testing, then clearly your testing didn’t have complete coverage; but you don’t know if the missing test coverage was for an error path or a functional path. The conservative choice is to assume it was an error case you were missing.
@kme, all known error cases must also be tested (note I’m assuming good tests and that IMHO is a prerequisite for them to be good). Also, aborting a request is one things, aborting the process is another.
Also, all those concerns are bundled in the assumption of being able to automatically find a “safe alternative”, which I will grant is a non-trivial research project all it’s own.
bcs: The very fact that you hit code that was dead in testing indicates that your assumption has been violated, so you can’t rely on it anymore.
Empirically not 100% true:
void RequestProcessor::ParseRequest(Req *req) {
…
RiskySubRequest sreq;
if (req.Parse(&sreq) {
sreq.DoRiskyThing();
}
…
}
Given code of that structure where, under proper usage, the then-clause never runs, you can just drop the whole thing or just skip the interior of the if. The most likely result from that transformation is to give a malformed response or trip error handling further down the line. For a non trivial number of cases, that could well be safer than allowing DoRiskyThing or opening up a DoS vector.
The question then becomes; is it possible to automatically identify cases where that class of transformation is safer that the alternatives?
OTOH, if you know something about the code, you might be able to hook into the per-request error handling and trigger it rather than taking down the server.
(Note, I’m assuming the cost to process each query is several order of magnitude less than the cost to restart the server. As is the case for most of the stuff I work on.)