One of the things I’ve been doing at Trust-in-Soft is looking for defects in open-source software. The program I’ve spent the most time with is SQLite: an extremely widely deployed lightweight database. At ~113 KSLOC of pointer-intensive code, SQLite is too big for easy static verification. On the other hand, it has an incredibly impressive test suite that has already been used to drive dynamic tools such as Valgrind, ASan, and UBSan. I’ve been using these tests with tis-interpreter.
Here I try to depict the various categories of undefined behaviors (UBs) where this post is mainly about the blue-shaded area:
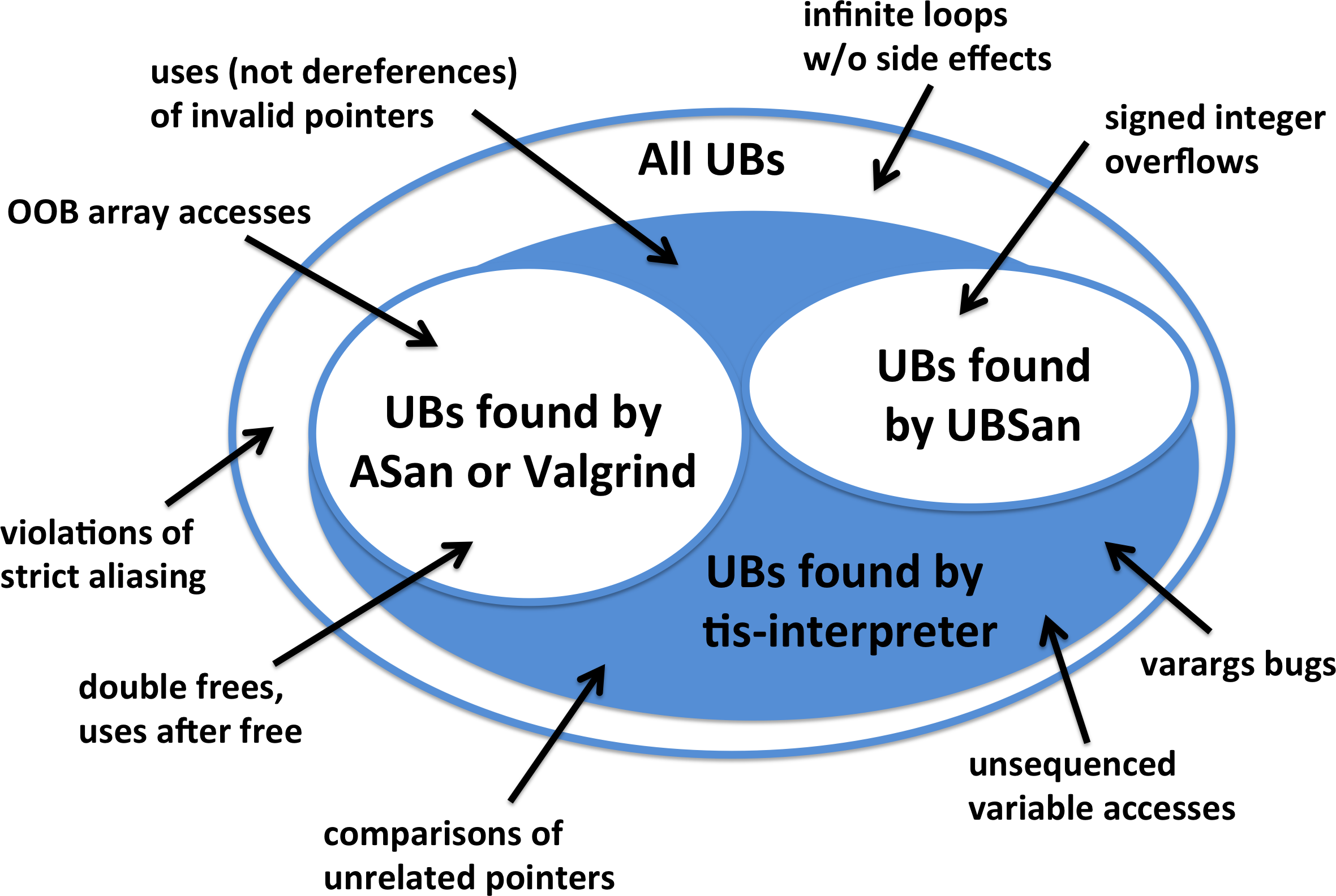
This figure leaves out many UBs (there are a few hundred in all) and is not to scale.
For honesty’s sake I should add that using tis-interpreter isn’t painless (it wasn’t designed as a from-scratch C interpreter, but rather is an adaptation of a sound formal methods tool). It is slower even than Valgrind. It has trouble with separately compiled libraries and with code that interacts with the system, such as mmap() calls. As I tried to show in the figure above, when run on code that is clean with respect to ASan and UBSan, it tends to find fiddly problems that a lot of people aren’t going to want to hear about. In any case, one of the reasons that I’m pushing SQLite through tis-interpreter is to help us find and fix the pain points.
Next let’s look at some bugs. I’ve been reporting issues as I go, and a number of things that I’ve reported have already been fixed in SQLite. I’ll also discuss how these bugs relate to the idea of a Friendly C dialect.
Values of Dangling Pointers
SQLite likes to use — but not dereference — pointers to heap blocks that have been freed. It did this at quite a few locations. For example, at a time when zHdr is dangling:
if( (zHdr>=zEndHdr && (zHdr>zEndHdr
|| offset64!=pC->payloadSize))
|| (offset64 > pC->payloadSize)
){
rc = SQLITE_CORRUPT_BKPT;
goto abort_due_to_error;
}
These uses are undefined behavior, but are they compiled harmfully by current C compilers? I have no evidence that they are, but in other situations the compiler will take advantage of the fact that a pointer is dangling; see this post and also Winner #2 here. You play with dangling pointers at your own risk. Valgrind and ASan make no attempt to catch these uses, as far as I know.
Using the value of a dangling pointer is a nettlesome UB, causing inconvenience while — as far as I can tell — giving the optimizer almost no added power in realistic situations. Eliminating it is a no-brainer for Friendly C.
Uses of Uninitialized Storage
I found several reads of uninitialized storage. This is somewhere between unspecified and undefined behavior.
One idiom was something like this:
int dummy;
some sort of loop {
...
// we don't care about function()'s return value
// (but its other callers might)
dummy += function();
...
}
// dummy is not used again
Here the intent is to avoid a compiler warning about an ignored return value. Of course a better alternative is to initialize dummy; the compiler can still optimize away the unwanted bookkeeping if function() is inlined or otherwise specialized.
At least one uninitialized read that we found was potentially harmful, though we couldn’t make it behave unpredictably. Also, it had not been found by Valgrind. Both of these facts — the predictability and the lack of an alarm — might be explained by the compiler reusing a stack slot that had previously contained a different local variable. Of course we must not count on such coincidences working out well.
A Friendly C could ignore reads of uninitialized storage based on the idea that tool support for detecting this class of error is good enough. This is the solution I would advocate. A heavier-handed alternative would be compiler-enforced zeroing of heap blocks and automatic variables.
Out-of-Bounds Pointers
In C you are not allowed to compute — much less use or dereference — a pointer that isn’t inside an object or one element past its end.
SQLite’s vdbe struct has a member called aMem that uses 1-based array indexing. To avoid wasting an element, this array is initialized like this:
p->aMem = allocSpace(...); p->aMem--;
I’ve elided a bunch of code, the full version is in sqlite3VdbeMakeReady() in this file. The real situation is more complicated since allocSpace() isn’t just a wrapper for malloc(): UB only happens when aMem points to the beginning of a block returned by malloc(). This could be fixed by avoiding the 1-based addressing, by allocating a zero element that would never be used, or by reordering the struct fields.
Other out-of-bounds pointers in SQLite were computed when pointers into character arrays went past the end. This particular class of UB is commonly seen even in hardened C code. It is probably only a problem when either the pointer goes far out of bounds or else when the object in question is allocated near the end of the address space. In these cases, the OOB pointer can wrap, causing a bounds check to fail to trigger, potentially causing a security problem. The full situation involves an undesirable UB-based optimization and is pretty interesting. A good solution, as the LWN article suggests, is to move the bounds checks into the integer domain. The Friendly C solution would be to legitimize creation of, and comparison between, OOB pointers. Alternately, we could beef up the sanitizers to complain about these things.
Illegal Arguments
It is UB to call memset(), memcpy(), and other library functions with invalid or null pointer arguments. GCC actively exploits this UB to optimize code. SQLite had a place where it called memset() with an invalid pointer and another calling memcpy() with a null pointer. In both cases the length argument was zero, so the calls were otherwise harmless. A Friendly C dialect would only require each pointer to refer to as much storage as the length argument implies is necessary, including none at all.
Comparisons of Pointers to Unrelated Objects
When the relational operators >, >=, <, <= are used to compare two pointers, the program has undefined behavior unless both pointers refer to the same object, or to the location one past its end. SQLite, like many other programs, wants to do these kinds of comparisons. The solution is to reduce undefined behavior to implementation defined behavior by casting to uintptr_t and comparing the resulting integers. For example, SQLite now has this method for checking if a pointer (that might be to another object) lies within a memory range:
# define SQLITE_WITHIN(P,S,E) \
((uintptr_t)(P)>=(uintptr_t)(S) && \
(uintptr_t)(P)<(uintptr_t)(E))
Uses of this macro can be found in btree.c.
With respect to pointer comparisons, tis-interpreter’s (and Frama-C’s) intentions are stronger than just detecting undefined behavior: we want to ensure that execution is deterministic. Comparisons between unrelated objects destroy determinism because the allocator makes no guarantees about their relative locations. On the other hand, if the pair of comparisons in a SQLITE_WITHIN call is treated atomically, and if S and E point into the same object, there is no determinism violation. We added a “within” builtin to Frama-C that can be used without violating determinism and also a bare pointer comparison that — if used — breaks the guarantee that Frama-C’s results hold for all possible allocation orders. Sound analysis of programs that depend on the relative locations of different allocated objects is a research problem and something like a model checker would be required.
In Friendly C, comparisons of pointers to unrelated objects would act as if they had already been cast to uintptr_t. I don’t think this ties the hands of the optimizer at all.
Summary
SQLite is a carefully engineered and thoroughly tested piece of software. Even so, it contains undefined behaviors because, until recently, no good checker for these behaviors existed. If anything is going to save us from UB hell, it’s tools combined with developers who care to listen to them. Richard Hipp is a programming hero who always responds quickly and has been receptive to the fiddly kinds of problems I’m talking about here.
What to Do Now
Although the situation is much, much better than it was five years ago, C and C++ developers will not be on solid ground until every undefined behavior falls into one of these two categories:
- Erroneous UBs for which reliable and ubiquitous (but perhaps optional and inefficient) detectors exist. These can work either at compile time or run time.
- Benign behaviors for which compiler developers have provided a documented semantics.
28 responses to “SQLite with a Fine-Toothed Comb”
Huh. I hadn’t thought much about the comparing pointers ub.
Does this mean that std:: set or similar are undefined?
The reference to the uninitialized memory reminded me of
http://research.swtch.com/sparse
which describes an array data-structure which gets its complexity guarantees (constant vs linear) _because_ it does not initialize the main part of the memory it uses.
On “compiler-enforced zeroing of heap blocks and automatic variables.” there is also the Memory talk about the Mill CPU-to-be-maybe, at
http://millcomputing.com/docs/memory/
where the CPU itself can supply the zeros on read, in some situations.
Argh, your formatter ate my type: “does this mean that a std::set of pointer-to-char or similar are undefined”?
Forbidding the use of dangling pointers does not improve optimization; it just describes existing hardware.
On architectures like Intel’s (16-bit) protected mode, loading the segment part of a pointer register already triggers an access check.
Andrew Hunter: I think the answer is no because std::less is able to compare pointers even if they do not point to the same object or array. See http://en.cppreference.com/w/cpp/utility/functional/less especially the part under specialization
John Regehr: Thank you for your excellent research bringing attention to undefined behavior. I find this article very scary. SQLite is in my opinion the highest quality major open source C project. SQLite’s approach to correctness borders on fanatical ( they have 800 lines of test code for every line of library code). It is also one of the most widely deployed pieces of code (there are probably around a billion instances of SQLite running right now). If despite this, there is still undefined behavior, what hope does any C or C++ project have of not having undefined behavior? I hope that the ISO C++ subcommittee SG12:Undefined and Unspecified Behavior is working with you to come up with a plan to minimize undefined behavior in C++.
Hi Andrew, as John says, std::less is “more defined” than the regular < operator and it works across different allocated objects, so the STL is on solid ground here. Strange but true!
Would rewriting SQLite using Rust help? I have heard that Rust’s security is nearly invincible.
I’m trying hard to think of a legitimate case where you’d need to know the relative positions in memory of unrelated allocated objects. The only thing I can think of is some kind of allocator test: “Did these things get allocated “upward from the bottom of memory” (or whatever the algorithm is supposed to be)?” This in turn suggests a whole category of what I’ll call “meta-programs,” programs that are written to examine the behavior of the facilities used to write them. It’s not clear whether these fall into the same category as ASan, UBSan, et al; my gut feeling is that they’re on a slightly different axis; but it seems conceivable that they might actually play by somewhat different rules than “normal” code, and that one solution might be to have a compiler mode, or a whole different (but related) compiler, for building these sorts of programs than for ordinary programs.
Too, I’m not fond of having to know and use a whole suite of tools to craft good code. I’m old(-school) and miss the “good ol’ days when we got by with a plain text editor and a command line,” tongue-in-cheek of course. I’d honestly rather see compilers catch as much UB as possible — and why not? They’re in the perfect position to do so: they know what the source code is telling them to implement; they know what code they’re generating / have generated at any given point in the compilation; and they know what optimizations they’re performing, and why. At the very least, compilers could report these things at compile time, rather than waiting for a whole separate tool to rediscover them — or not! — after-the-fact. (It is also possible that the tools you’re talking about actually work this way already; I don’t know anything about them.)
> Here the intent is to avoid a compiler warning about an ignored return value.
One might wonder why they didn’t just cast the return value to (void), which is a traditional and clearer way of signifying that the return value is intentionally being ignored. It’s because the GCC maintainers don’t believe that the end user should be allowed to do so, and don’t really care what other tools do or have done:
Andrew Pinski 2015-06-11 06:06:27 UTC (In reply to Filipe Brandenburger)
> > And it’s not just LLVM… Other linters and static analysis tools seem to
>> agree that a (void) cast is an explicit indication that the coder meant to
>> ignore those results, so why would gcc want to be the one exception here?
>
> Again this has nothing to do with other lints, this attribute was designed
> so you can’t ignore the return value. And most lints/static analysis tools
> will also look to see if you not really ignoring the return value in that you
> use it in an error case fashion. casting to void does not always cause (and
> really should not cause) static analysis to ignore what you did was broken
> for the API. It is not GCC’s fault people are starting to misuse this
> attribute; you should write into those projects instead saying they are
> misunderstanding the attribute is being used incorrectly. I bet some of
> them, really don’t want a warning even with a cast to void.
https://gcc.gnu.org/bugzilla/show_bug.cgi?id=66425.
Personally, I think this is a clear case where allowing the user to safely suppress the warning with (void) would have a better end result than introducing undefined behavior.
Rewriting SQLite in Rust, or some other trendy “safe” language, would not help. In fact it might hurt.
Prof. Regehr did not find problems with SQLite. He found constructs in the SQLite source code which under a strict reading of the C standards have “undefined behaviour”, which means that the compiler can generate whatever machine code it wants without it being called a compiler bug. That’s an important finding. But as it happens, no modern compilers that we know of actually interpret any of the SQLite source code in an unexpected or harmful way. We know this, because we have tested the SQLite machine code – every single instruction – using many different compilers, on many different CPU architectures and operating systems and with many different compile-time options. So there is nothing wrong with the sqlite3.so or sqlite3.dylib or winsqlite3.dll library that is happily running on your computer. Those files contain no source code, and hence no UB.
The point of Prof. Regehr’s post (as I understand it) is the the C programming language as evolved to contain such byzantine rules that even experts find it difficult to write complex programs that do not contain UB.
The rules of rust are less byzantine (so far – give it time :-)) and so in theory it should be easier to write programs in rust that do not contain UB. That’s all well and good. But it does not relieve the programmer of the responsibility of testing the machine code to make sure it really does work as intended. The rust compiler contains bugs. (I don’t know what they are but I feel sure there must be some.) Some well-formed rust programs will generate machine code that behaves differently from what the programmer expected. In the case of rust we get to call these “compiler bugs” whereas in the C-language world such occurrences are more often labeled “undefined behavior”. But whatever you call it, the outcome is the same: the program does not work. And the only way to find these problems is to thoroughly test the actual machine code.
And that is where rust falls down. Because it is a newer language, it does not have (afaik) tools like gcov that are so helpful for doing machine-code testing. Nor are there multiple independently-developed rust compilers for diversity testing. Perhaps that situation will change as rust becomes more popular, but that is the situation for now.
but I bet your analysis tool still fails like all other compilers doing…..
void f() {
int will_be_initialzed;
int i;
for( i = 0; i < 2; i++ ) { if( i == 0 ) will_be_initialized = 1234; }
printf( "%d", will_be_initialized );
}
There is certainly no path that the printf will happen that the variable won't have a value; yet code analyzers will say it's possibly uninitialized.
> I’m trying hard to think of a legitimate case where you’d need
> to know the relative positions in memory of unrelated allocated objects.
What about when you’re writing a memory allocator?
Mind defining the term “UB” before using it repeatedly assuming *of course* everyone know what it is. Yes, that last comment finally typed out “undefined behavior”. But the rule I follow is type out the first instance and the stater using initialisms. Thanks.
I’ve expanded out undefined behavior, thanks.
d3x0r, of course tis-interpreter does not fall down on your example, which is designed to fool a static analyzer, not a checking interpreter.
Cervisia, thanks! I knew there must be a platform that justified that decision, but didn’t know what is was. But the real question is whether the requirements of a couple of obsolete platforms needs to create difficulties for everyone…
Richard, I think I can characterize your position as something like “If the code compiles and works today, then by definition it’s not buggy.” I think you should recognize that this is a somewhat extreme position, or at least pretty far towards one end of a spectrum.
Many C compiler developers would take almost the opposite view, something like “any undefined behavior might invalidate all guarantees made by the compiler, because we assume that the program doesn’t do them.” From this point of view, every UB is a serious bug that might result in exploitability.
My own views are captured in the “What To Do Now” section at the end!
John, my views are distorted by 6 years of relentless focus on MC/DC. In that context, UB is like compiler warnings or compiler bugs – issues that should be dealt with but which are not existential threats to the project since they all occur upstream from the point of verification.
When working on other (normal) projects (example: Fossil) where the point of verification is the logical correctness of the source code, then I completely agree that UB should be religiously avoided, since it occurs downstream from the verification point.
The “dummy +=” construct is a bit strange. Isn’t it idiomatic to ignore return values with a (void) cast?
I would rather describe Richard’s position as “I cannot trust the compilers, so I test the binaries; the source code may have UBs or run into compiler bugs, but I know the binaries I distribute are correct because they were thoroughly tested”. This is still an extreme position in the sense that very few programmers have the tests in place to be able to hold it, but the shift from “correct source code” to “correct results of compilation” certainly make sense to some other people — I would suppose this is why some part of the areospace industry checks the compiler programs in addition to the source.
Of course correctness of the binaries produced today says nothing of the binaries produced tomorrow, if either the source or the compilers change. Richard was pointing out that ruling out UBs does not suffice to establish trust, and that binary-level testing may very well still be necessary after moving to a “friendlier” language.
Richard (and gasche) I understand and sympathize with this point of view and I agree that — when you have done a very good job testing — it has a lot of merit. And it is the overall very high quality of SQLite that makes it so suitable for use in a study like the one I’m doing.
If I were to nitpick your argument about trusting the binary, I’d do it along two lines. First, there are people building SQLite from source, using random compilers + compiler options, who do not have access to the full test suite. Second, any collection of tests, no matter how good, will miss some bugs.
Are the bugs missed by your tests caused by compilers exploiting undefined behaviors? Maybe not, but only time will tell and in the meantime it seems like a great idea to eliminate those behaviors.
> it seems like a great idea to eliminate those behaviors.
I agree. And to that end, all known UB in SQLite has been removed (sometimes grudgingly, I admit, though please do let me know if you see anything new or anything old that I’ve missed).
The disagreement is not over whether or not UB is a problem, but rather how serious of a problem. Is it like “Emergency patch – update immediately!” or more like “We fixed a compiler warning” or is it something in between.
Note that the equality comparisons != and == are well-defined even for pointers into different objects – it’s only the relational comparisons.
I believe one of the reasons is that this allows an implementation where a pointer value is a tuple consisting of an object identifier and an offset within that object. The equality operators would have to test both parts of the pointers to be compared, but the relational operators can get away with just comparing the offsets. The “UB” comes into it because you might then have pointers where p
I think there is another requirement to escape UB hell: no implicit UB.
The standard should be expected to explicitly call out all UB cases, leaving nothing as UB by lack of comment.
> The standard should be expected to explicitly call out all UB cases,
> leaving nothing as UB by lack of comment.
The compiler does not always know. For example:
int pow2int(int x){ return 1<<x; }
The compiler (usually) has know way of knowing if parameter x will be greater than the number of bits in an integer.
Oh, my comparison operators were eaten by a grue. I meant to say “…where p ≺ q, p ≻ q and p == q are all false”.
bcs, the “no implicit UB” rule is a good one, and seems like common sense — it’s insane to define a programming language giving the compiler license to kill in situations not even described in the standards.