[Note: I promise, this is almost my last post about undefined behavior for a while. Maybe just one more in the queue.]
The current crop of C and C++ compilers will exploit undefined behaviors to generate efficient code (lots of examples here and here), but not consistently or well. It’s time for us to take this seriously. In this piece I’ll show that aggressively exploiting undefined behavior can massively speed up real codes, while remaining 100% faithful to the language standards.
Since undefined behavior is tricky to talk about, I’ll need to lay a bit of groundwork.
Understanding a C or C++ Program
The meaning of a C or C++ program is determined by an “abstract machine” that is described in the standards. You can think of these abstract machines as the simplest possible non-optimizing interpreters for C and C++. When the abstract machine runs a program, it does so as a sequence of steps, each of which is stated or implied by the standard. We’ll call this sequence of steps an execution. In general, a program will admit many different executions. For example, if we use gzip to compress the Gettysburg Address, the C abstract machine will perform a few million steps which together constitute one possible execution of gzip. If we compress the Gettysburg Address again, we’ll get the same execution (in this post we’ll ignore the fact that these abstract machines are non-deterministic). If we compress “I Have a Dream” then we’ll get a different execution. It is useful to talk about the set of all possible executions of a program. Of course, this set often has a large or infinite number of members.
The Compiler’s Job
The compiler’s job is to emit object code that has the same observable behavior as the C/C++ abstract machine for all non-erroneous executions of the program. Observable behavior is pretty much just like it sounds: it covers the abstract machine’s interactions with hardware (via volatile variables), the operating system, etc. Internal operations such as incrementing a variable or calling malloc() are not considered to be observable. The compiler is free to generate any code it likes as long as observable behaviors are preserved. Consequently, the compiler does not need to translate code that is not touched by any execution of the program. This is dead code elimination, a useful optimization.
Now let’s work undefined behavior into the picture. Every execution step performed by the C/C++ abstract machine is either defined or undefined. If an execution of a program contains any undefined steps, then that execution is erroneous. The compiler has no obligations at all with respect to erroneous executions. Notice that “erroneous” is an all-or-nothing property; it’s not the case that an execution is non-erroneous up to the point where it executes an operation with undefined behavior. (I wrote about this issue in more detail here.)
As a thought experiment, let’s take an arbitrary C or C++ program and add a new line of code at the start of main():
-1<<1;
To evaluate this expression, the abstract machine must perform an operation that (in the C99, C11, and C++11 dialects) has undefined behavior. Every execution of the program must evaluate this expression. Thus, the program admits no non-erroneous executions. In other words, the compiler has no obligations. An efficient course of action for the compiler would be to report success without generating any object code.
What if we put the undefined execution at the end of the program, just before main() returns? Assuming that the program contains no calls to exit() or similar, this has exactly the same effect—the compiler can report success and exit without generating any code.
Do Real Codes Have Lots of Erroneous Executions?
Let’s consider the SPEC benchmark programs. Making them fast is something that most compiler vendors would like to do. Using IOC we found that a majority of the programs in SPEC CINT 2006 execute undefined behavior during the course of a “reportable” run. This means that a correct C/C++ compiler could generate code that is almost infinitely faster than the code generated by current compilers. The SPEC harness would of course complain that the compiled programs produce the wrong results, but this is actually a bug in the SPEC harness, not a bug in the compilers. If we insist that a compiler turns these SPEC programs into executables that produce the specified results, then we are effectively mandating that this compiler implements a bizarre, undocumented dialect of C where undefined behavior can sometimes be exploited and sometimes not.
If we consider them to be written in C99, LLVM/Clang 3.1 and GCC (SVN head from July 14 2012), running on Linux on x86-64, do not appear to admit any non-trivial, non-erroneous executions. I expect the same is true of most or all previous versions of these compilers. IOC tells us that these compilers execute undefined behaviors even when compiling an empty C or C++ program with optimizations turned off. The implication is that a suitably smart optimizing compiler could create executables for Clang and GCC that are dramatically faster than the executables we use every day. Think how fast you could build a Linux kernel with one of these compilers!
My guess is that most or all executions of GCC and LLVM (and basically all other large programs) would be undefined by C89 (and not just C99) but we can’t tell for sure without using a comprehensive undefined behavior checker for C89. This tool does not exist. I confess to not personally having the gumption necessary for cramming GCC or LLVM through the best available dynamic undefined behavior checkers: KCC and Frama-C.
How Optimizing Compilers Should Work
Compilers are perfectly capable of reasoning about all possible executions of the program being compiled. They do this with static analysis, which avoids decidability problems using approximation. In other words, detecting dead code is perfectly possible as long as we accept that there will sometimes be dead code that we cannot statically detect. The resulting optimization, dead code elimination, is ubiquitous in optimizing compilers. So how can we leverage static analysis to aggressively exploit undefined behavior?
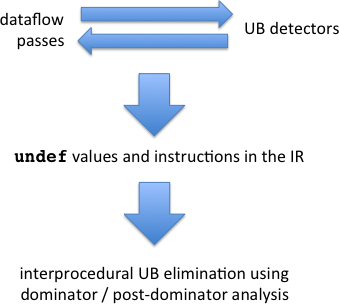
Step 1: Make Undefined Behavior Explicit in the IR
LLVM already has a limited form of explicit undefinedness: an “undef” value. This is useful but it should be augmented with an undef instruction that represents unconditional execution of undefined behavior.
[Update: Owen Anderson points out in the comments that LLVM’s unreachable instruction already serves this purpose! Cool. Also, the undef value has stronger semantics than C/C++ undefined behavior so either its meaning would need to be tweaked or else a new value would need to be added before the undef to unreachable promotion I mention below would work.]
Step 2: Turn Dataflow Facts into Undefined Behaviors
Compilers already turn undefined behaviors into dataflow facts. For example, in the famous example from the Linux kernel, GCC used a pointer dereference to infer that the pointer was not null. This is all good, though there are plenty of instances where compilers could be much more aggressive about this; Pascal has a nice example involving restrict.
On the other hand, not as much has been done on aggressively inferring undefined behavior using dataflow facts. For example:
- If a program evaluates x+y and we know that both x and y are larger than 1.1 billion (and both variables are 32-bit ints), the addition can be replaced with an undef value.
- If a program evaluates (*x)++ & (*y)++ and the pointer analysis can show that x and y are aliases, the expression can again be turned into an undef value.
- Any statement that unconditionally evaluates an expression containing an undef value can be turned into an undef instruction.
There are around 191 kinds of undefined behavior in C99, so a complete set of optimization passes looking for them will require a fair amount of work.
Step 3: Prune Undefined Executions
Now we want to delete any code that is only needed by erroneous executions. This will build upon dominator analysis, which is already done by optimizing compilers. A piece of code X dominates Y if you can only get to Y by first executing X. All code that is dominated by an undef instruction can be removed. The opposite is not true: code can’t be deleted just because it dominates an undef. However, there exists a reversed dominator analysis called post dominator where X post-dominates Y when all executions going through X must also go through Y afterwards. Using the results of this analysis, we can safely delete any code that post-dominates an undef.
Dominator-based undefined behavior optimization will be particularly effective when used interprocedurally at link time. For example, if I write a function that unconditionally uses an uninitialized variable, the intraprocedural analysis will reduce that function to a single undef instruction, but the interprocedural optimization will potentially be able to destroy much more code: everything leading up to, and away from, calls to this function, across the whole program. Imagine what could be accomplished if a common C library function such as malloc(), in a widely deployed version of libc, could be shown to unconditionally execute undefined behavior: almost all C programs on that system would totally disappear. A real Linux distribution could be fit onto a couple of floppy disks, like in the old days.
The big picture is something like this:
Conclusions
Let me be clear: compilers already try to avoid generating code corresponding to erroneous executions. They just don’t do this very well. The optimizations that I’m proposing differ in degree, not in kind.
Perhaps I’ll get a student to implement the more aggressive optimizations as a proof of concept. We’ll impress everyone with 2-second builds of the Linux kernel, 3-second GCC bootstraps, and 99.9% code-size reductions for Firefox.
29 responses to “It’s Time to Get Serious About Exploiting Undefined Behavior”
The following bullet point is very confusing, could you please clarify?
> If a program evaluates *x = *y and the pointer analysis can show that x and y are aliases, the expression can again be turned into an undef value.
Hi, John.
I have not seen these SPEC bugs you have found. Could they be in operations that most compilers still promote from “undefined” to “implementation-defined”, similar to what Joseph Myers said in http://gcc.gnu.org/bugzilla/show_bug.cgi?id=54027 ? If they are in clearly undefined (already exploited for optimization) operations, then yes, someone should kick that particular anthill.
Step 2 is already implemented in Frama-C’s value analysis: at any program point you can observe the values any lvalue can take FOR DEFINED EXECUTIONS THAT REACH THAT POINT. If you call the function f2() in my example either with arguments &a, &a or with &b, &c, it will tell you that p is always &b and q is always &c after the “check”. By simply, while optimizing the body of f2(), querying the value analysis for values of p and q, a compiler would automatically generate the good code that returns the constant 3 (in this particular example the value analysis would also tell the compiler that the returned expression is always 3).
“it’s not the case that an execution is non-erroneous up to the point where it executes an operation with undefined behavior”
This is quite subtle. Schrödinger-esque even. A particular execution is neither erroneous nor correct until it either terminates correctly (in which case it was correct), or performs an undefined operation (in which case it was erroneous to begin with!?). And if it does not terminate, but keeps executing correctly, it’s correct? 😀
For instance, consider the following pseudo-code:
// repeatedly {
// ask for user input
// if user input is 42, perform undefined operation
// }
What would that piece of code qualify as?
LLVM already has an “undef instruction”; it’s called “unreachable”.
However, turning expressions containing undef into unreachable is not sound. There are legitimate uses of undef that do not represent completely undefined behavior. For instance, constructing an aggregate value from individual fields involves starting with an undef initial value and inserting the fields into it.
Another important example is as the operands to PHI instructions, where the value to be joined is undefined on one side of the PHI, but well defined on the other. The presence of the undef expression does not turn the entire PHI expression into undefined behavior.
Hi amonakov, in C it is illegal to modify an object more than once (or to both modify and read it) unless there are intervening sequence points. So if x and y refer to the same object, that expression produces undefined behavior.
UPDATE: Sorry! This was a bug in my post. I’ve changed the example now.
Hi Owen: Yeah, I figured there were some semantic mismatches between undefined in LLVM and in C/C++. Things would have to be tweaked a bit to make this all work…
Hi Valentin, I’ll just paste my G+ response here:
It’s even worse than you say. An infinite loop is undefined unless it executes operations that are observable:
http://blog.regehr.org/archives/161
http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1528.htm
And this is in practice, not in theory! All optimizing compilers do it.
I don’t think we can classify your pseudocode statically, but of course at runtime we can classify individual executions.
However, even dynamic detection of undefined behavior is intractable (for a single threaded program) or undecidable (for multiple threads):
https://www.ideals.illinois.edu/handle/2142/30780
Summary: even if you understand the situation, it is strictly worse than you think.
“it’s not the case that an execution is non-erroneous up to the point where it executes an operation with undefined behavior”
Meditating on the semantics of
P;
assume(false)
helps.
Actually, scratch that. I’m mixing how assume is sometimes treated in constraint solver translations with the standard semantics, where it just doesn’t terminate. The undefined behavior is more peculiar.
Hi Pascal, if you push SPEC CINT through IOC in C99 mode, lots of problems show up (plenty in C89 mode also). We discuss this all pretty thoroughly in the IOC paper.
Hi Alex, I definitely do not pretend to understand all of the implications of undefined behavior’s effects reaching backwards. But I do not like it.
Darling, you are skating close to Bob Harper-like unreasonability on this topic. Do you think it’s a shameful travesty that the scourge of undefined behavior continues to exist? You’re either making a joke or a slippery slope argument; I like the joke but the slippery slope argument (LOOK WHAT RETARDED CRAP RETARDED OPTIMIZERS COULD DO!!) seems weak.
Hi Eddie! Not exactly a joke, but more like a modest proposal.
Also it was not acceptable to me that Pascal got to write the funniest undefined behavior essay this week. http://blog.frama-c.com/index.php?post/2012/07/25/On-the-redundancy-of-C99-s-restrict
I, for one, won’t complain if you have several more undefined behavior posts in the pipeline.
*x = *y when x and y alias is just the same as writing something like i = i. But i = i is just as defined as i = i + 1. I.e., fine.
Hi Michael, thanks — I can never get the hang of the bit of the standard that makes “x = x” OK. I think it is fixed now.
Max, thanks. I just try to keep in mind that 99.99% of developers are not as fascinated by undefined behavior as I am.
You need a plan to take advantage of statements like func(x(), y()) where picking the right order of evaluation makes the program crash on the spot.
Nick, I love the idea of a hostile order of evaluation picker.
Of course this is exponential in the worst case but I bet for most real C programs the compiler could search all possible evaluation orders pretty quickly.
Ok, compilers could prune lots of code that can be treated as dead due to undefinedness. But why would we want that? Removing that code makes the program compiled behave *incorrect* according to the intention of the programmer.
Detecting undefinedness is great, but why destroy the program and let it execute? Can’t we just notify the programmer and make him *fix* the undef. behavior?
Hi tobi, there are several answers to your question.
First, the compiler cares little or nothing about our intentions. It only tries to take the code we wrote and make it run fast. Removing undefined code is therefore good because the remaining (well-defined) code should be smaller and faster.
Second, creating fast/small code and providing good diagnostics are almost totally separate jobs. For example, Chris Lattner did a nice job explaining why it’s hard for the compiler to tell the user when it is exploiting undefined behavior:
http://blog.llvm.org/2011/05/what-every-c-programmer-should-know_21.html
Finally, it is good that you have noticed that exploiting undefined behavior is a little bit absurd and is unlikely to result in code that respects our intentions. That was really the point of my post. The situation is already absurd!
Yeah it is insane although clearly it serves a good purpose. After all, C(++) is mainly chosen for performance and portability. Undefined behaviors are kind of required for both.
Why not make most currently undefined behaviors implementation defined? For example, the standard might say, that a signed overflow results in a value that is undefined (but it is still like any other value). That value multiplied by zero would be guaranteed to be zero. It cannot format the disk.
The same for shifts.
I can’t think of a way to make sensible things happen for *NULL, though. But at least some of the nastyness is gone.
Mentioning a “hostile order of evaluation picker” I never got to see it, but I’ve been told stories about a pathological compiler: each time you ran it, it would randomly make a new set of choices for every bit of implementation defined wiggle room (including things like integer widths). From what I heard, it got about the same results as IOC: nothing even past its own tests. OTOH it’ ouput tended to crash rather than generate bug reports.
Also, if anyone does code this all up it should be turned on with a -hostile flag (to go with the -pedantic flag)
Hi bcs, I’d love to read more about this compiler if you find a reference. Sounds excellent.
I’ve heard of a hostile GCC option that would push defs and uses back and forth along their dependency chains. I have no idea if this made it into any release–might have been for internal use at a compiler shop. I think it was called “uck”. Accessed using the -f prefix, of course.
I’ve used a demonic simulator for concurrent x86 code that tries to find poorly synchronized code. I heard about a different simulator that implemented a “wrong buffer” — a hostile variant of a write buffer, obviously.
Tobi, the sort of things you suggest would be steps in the right direction, certainly.
I have actually looked at something very similar to speed up dynamic symbolic execution of programs. If we are interested in doing a path exploration on a single component of a large program we can use ‘undef’ to remove code which is irrelevant. The way I have implemented it inside LLVM as a program analysis which I call a Change Value Analysis (CVA). I start from the return value(output) of the function (program) and then do a backward data flow analysis to mark all the instructions which depend on it as ‘Changed’. The rest of the instructions in the programs are marked ‘UnChanged’. Then I mark the uses of these ‘UnChanged’ instructions as ‘undef’. Existing Compiler optimization in LLVM (like Advanced Dead Code Elimination) can do a better job of optimizing the program by producing a smaller binary which leads to faster symbolic execution. I have used an existing symbolic execution engine (Fuzzgrind) for experiments and have some positive results for the SIR benchmark (Size reduction for 20-30% for same coverage of paths).
Provided the ‘undef’ instruction stop the execution (and provide some context to understand why it stopped) I think that it would be an interesting tool.
The reference was, unfortunately, talking with some random person I meet at lunch a year or so ago.