An optimizing, ahead-of-time compiler is usually structured as:
- A frontend that converts source code into an intermediate representation (IR).
- A target-independent optimization pipeline: a sequence of passes that successively rewrite the IR to eliminate inefficiencies and forms that cannot be readily translated into machine code. Sometimes called the “middle end.”
- A target-dependent backend that generates assembly code or machine code.
In some compilers the IR format remains fixed throughout the optimization pipeline, in others the format or semantics change. In LLVM the format and semantics are fixed, and consequently it should be possible to run any sequences of passes you want without introducing miscompilations or crashing the compiler.
The sequence of passes in the optimization pipeline is engineered by compiler developers; its goal is to do a pretty good job in a reasonable amount of time. It gets tweaked from time to time, and of course there’s a different set of passes that gets run at each optimization level. A longish-standing topic in compiler research is to use machine learning or something to come up with a better optimization pipeline either in general or else for a specific application domain that is not well-served by the default pipelines.
Some principles for pass design are minimality and orthogonality: each pass should do one thing well, and there should not be much overlap in functionality. In practice, compromises are sometimes made. For example when two passes tend to repeatedly generate work for each other, they may be integrated into a single, larger pass. Also, some IR-level functionality such as constant folding is so ubiquitously useful that it might not make sense as a pass; LLVM, for example, implicitly folds away constant operations as instructions are created.
In this post we’ll look at how some of LLVM’s optimization passes work. I’ll assume you’ve read this piece about how Clang compiles a function or alternatively that you more or less understand how LLVM IR works. It’s particularly useful to understand the SSA (static single assignment) form: Wikipedia will get you started and this book contains more information than you’re likely to want to know. Also see the LLVM Language Reference and the list of optimization passes.
We’re looking at how Clang/LLVM 6.0.1 optimizes this C++:
bool is_sorted(int *a, int n) {
for (int i = 0; i < n - 1; i++)
if (a[i] > a[i + 1])
return false;
return true;
}
Keep in mind that the optimization pipeline is a busy place and we’re going to miss out on a lot of fun stuff such as:
- inlining, an easy but super-important optimization, which can’t happen here since we’re looking at just one function
- basically everything that is specific to C++ vs C
- autovectorization, which is defeated by the early loop exit
In the text below I’m going to skip over every pass that doesn’t make any changes to the code. Also, we’re not even looking at the backend and there’s a lot going on there as well. Even so, this is going to be a bit of a slog! (Sorry to use images below, but it seemed like the best way to avoid formatting difficulties, I hate fighting with WP themes. Click on the image to get a larger version. I used icdiff.)
Here’s the IR file emitted by Clang (I manually removed the “optnone” attribute that Clang put in) and this is the command line that we can use to see the effect of each optimization pass:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
The first pass is “simplify the CFG” (control flow graph). Because Clang does not optimize, IR that it emits often contains easy opportunities for cleanup:
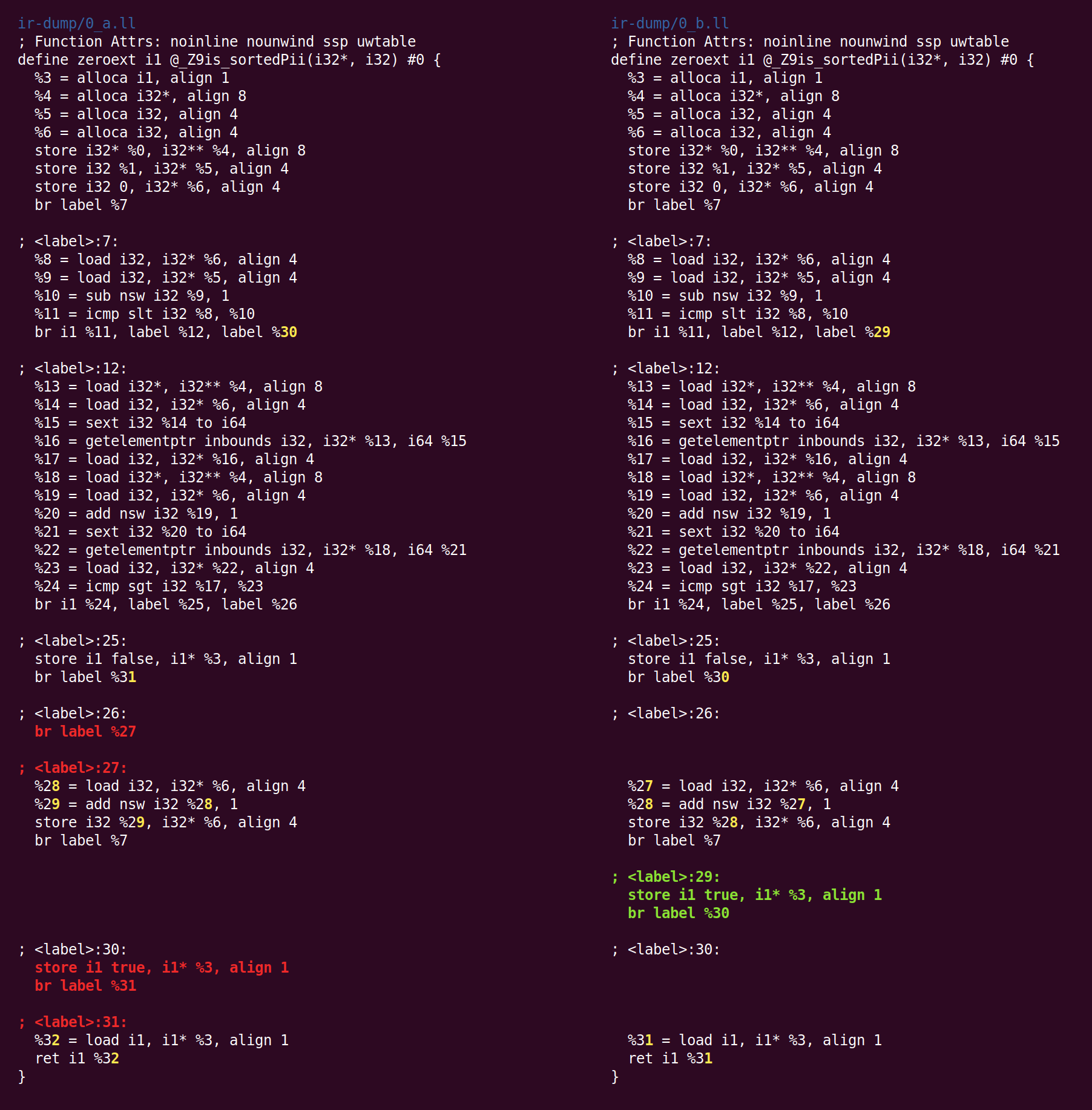
Here, basic block 26 simply jumps to block 27. This kind of block can be eliminated, with jumps to it being forwarded to the destination block. The diff is a bit more confusing that it would have to be due to the implicit block renumbering performed by LLVM. The full set of transformations performed by SimplifyCFG is listed in a comment at the top of the pass:
- Removes basic blocks with no predecessors.
- Merges a basic block into its predecessor if there is only one and the predecessor only has one successor.
- Eliminates PHI nodes for basic blocks with a single predecessor.
- Eliminates a basic block that only contains an unconditional branch.
- Changes invoke instructions to nounwind functions to be calls.
- Change things like “if (x) if (y)” into “if (x&y)”.
Most opportunities for CFG cleanup are a result of other LLVM passes. For example, dead code elimination and loop invariant code motion can easily end up creating empty basic blocks.
The next pass to run, SROA (scalar replacement of aggregates), is one of our heavy hitters. The name ends up being a bit misleading since SROA is only one of its functions. This pass examines each alloca instruction (function-scoped memory allocation) and attempts to promote it into SSA registers. A single alloca will turn into multiple registers when it is statically assigned multiple times and also when the alloca is a class or struct that can be split into its components (this splitting is the “scalar replacement” referred to in the name of the pass). A simple version of SROA would give up on stack variables whose addresses are taken, but LLVM’s version interacts with alias analysis and ends up being fairly smart (though the smarts are not needed in our example).
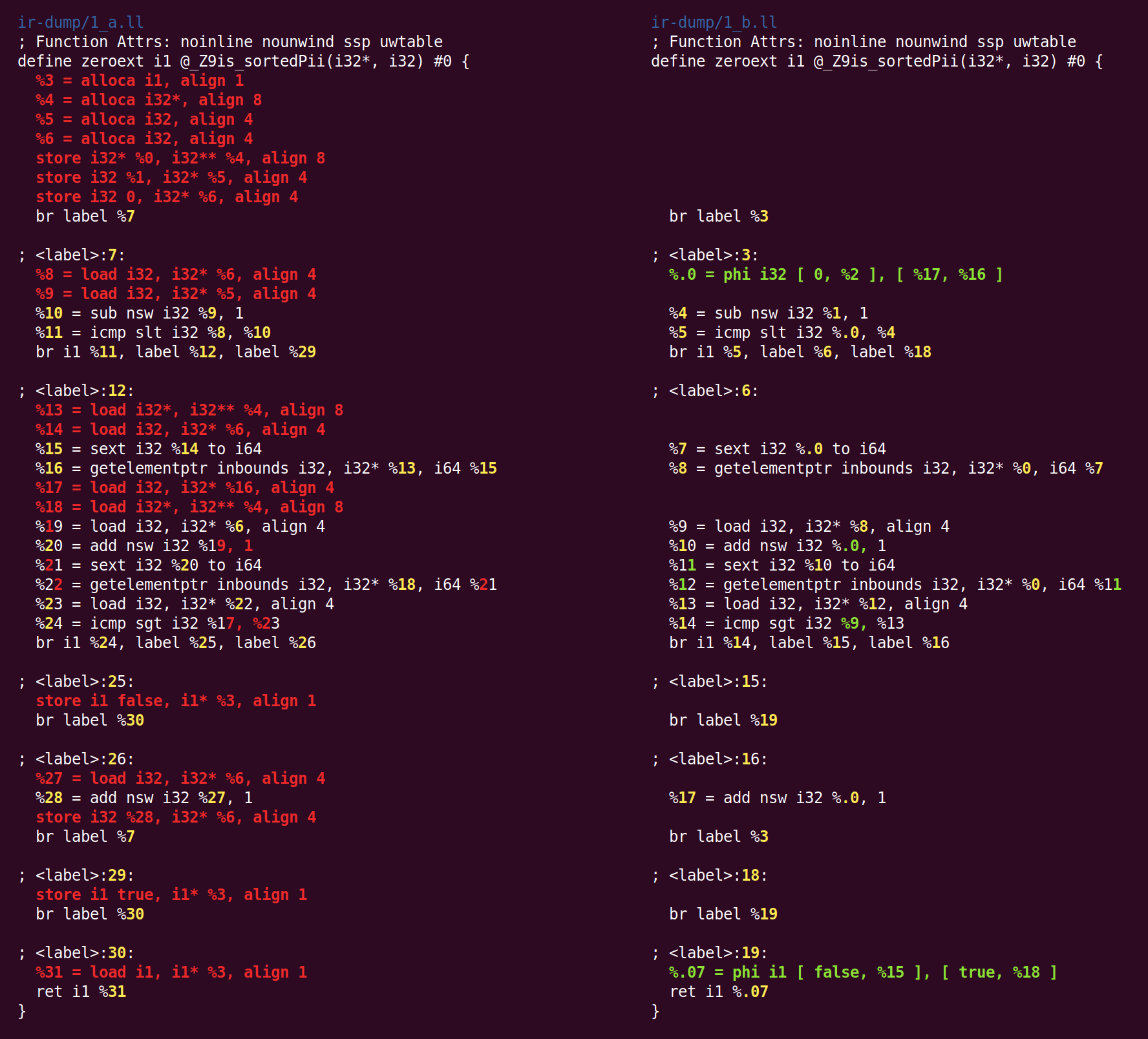
After SROA, all alloca instructions (and their corresponding loads and stores) are gone, and the code ends up being much cleaner and more amenable to subsequent optimization (of course, SROA cannot eliminate all allocas in general — this only works when the pointer analysis can completely eliminate aliasing ambiguity). As part of this process, SROA had to insert some phi instructions. Phis are at the core of the SSA representation, and the lack of phis in the code emitted by Clang tells us that Clang emits a trivial kind of SSA where communication between basic blocks is through memory, instead of being through SSA registers.
Next is “early common subexpression elimination” (CSE). CSE tries to eliminate the kind of redundant subcomputations that appear both in code written by people and in partially-optimized code. “Early CSE” is a fast, simple kind of CSE that looks for trivially redundant computations.
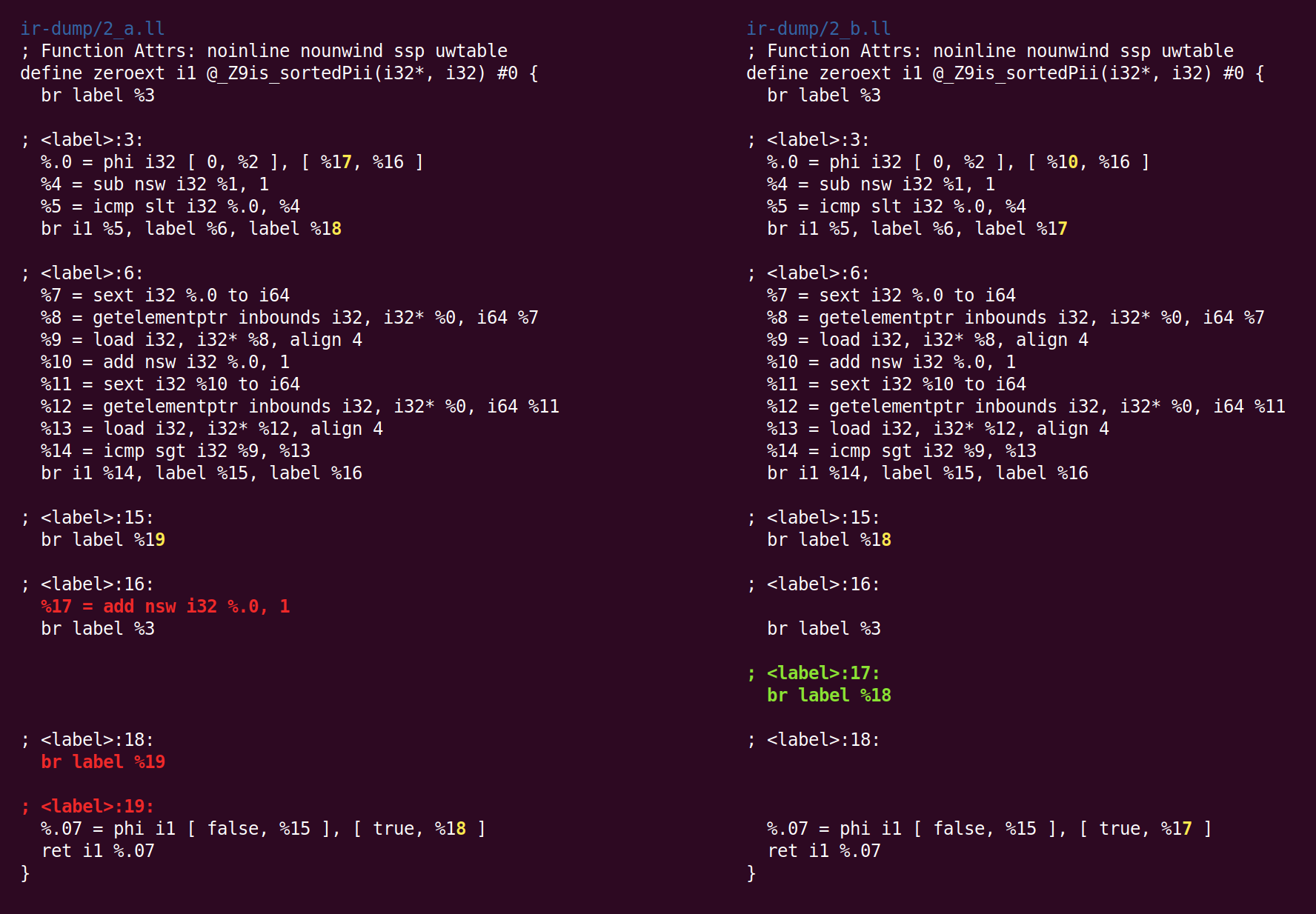
Here both %10 and %17 do the same thing, so uses of one of the values can be rewritten as uses of the other, and then the redundant instruction eliminated. This gives a glimpse of the advantages of SSA: since each register is assigned only once, there’s no such thing as multiple versions of a register. Thus, redundant computations can be detected using syntactic equivalence, with no reliance on a deeper program analysis (the same is not true for memory locations, which live outside of the SSA universe).
Next, a few passes that have no effect run, and then “global variable optimizer” which self-describes as:
It makes this change:
The thing that has been added is a function attribute: metadata used by one part of the compiler to store a fact that might be useful to a different part of the compiler. You can read about the rationale for this attribute here.
Unlike other optimizations we’ve looked at, the global variable optimizer is interprocedural, it looks at an entire LLVM module. A module is more or less equivalent to a compilation unit in C or C++. In contrast, intraprocedural optimizations look at only one function at a time.
The next pass is the “instruction combiner“: InstCombine. It is a large, diverse collection of “peephole optimizations” that (typically) rewrite a handful of instructions connected by data flow into a more efficient form. InstCombine won’t change the control flow of a function. In this example it doesn’t have a lot to do:
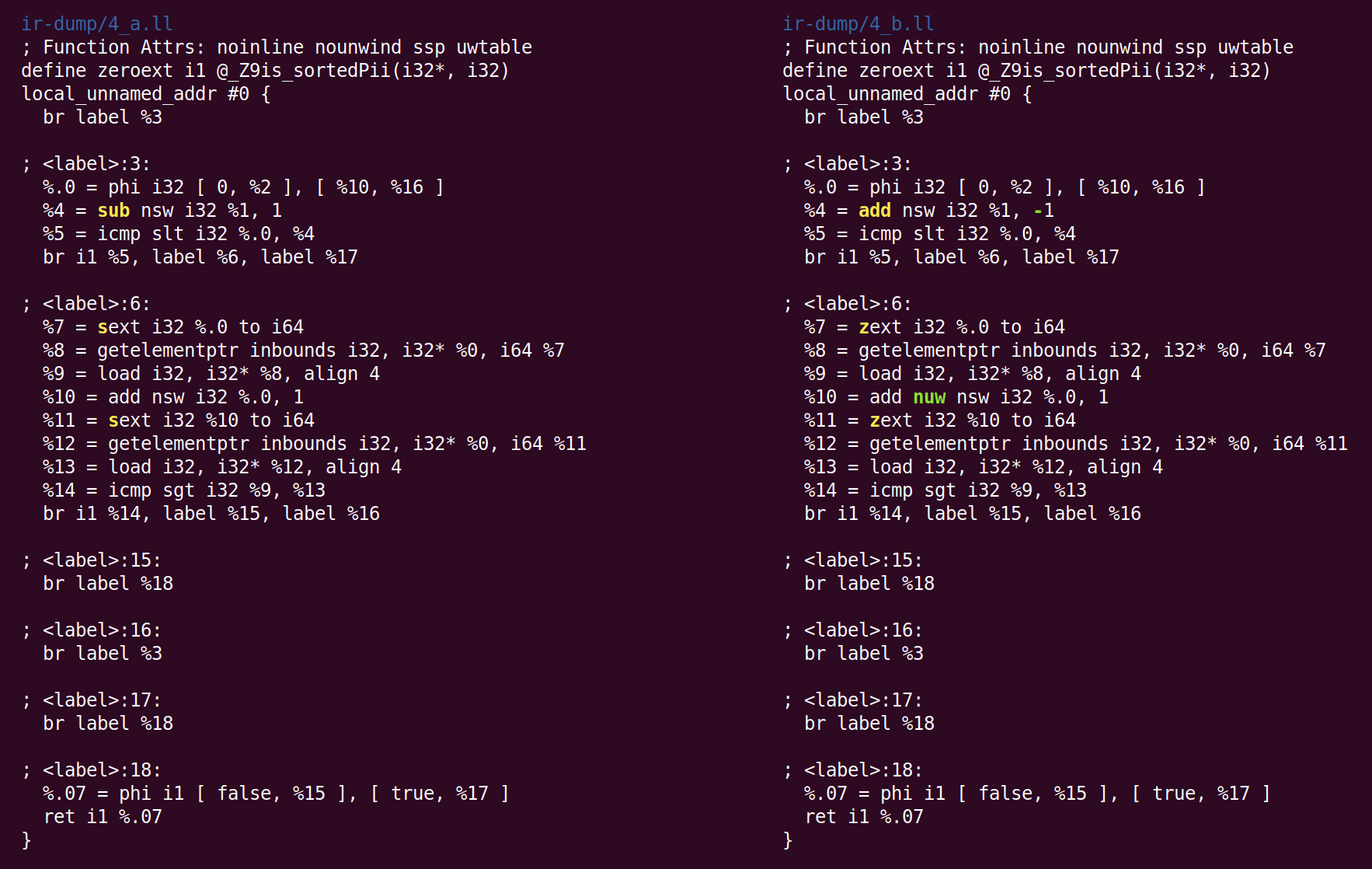
Here instead of subtracting 1 from %1 to compute %4, we’ve decided to add -1. This is a canonicalization rather than an optimization. When there are multiple ways of expressing a computation, LLVM attempts to canonicalize to a (often arbitrarily chosen) form, which is then what LLVM passes and backends can expect to see. The second change made by InstCombine is canonicalizing two sign-extend operations (sext instructions) that compute %7 and %11 to zero-extends (zext). This is a safe transformation when the compiler can prove that the operand of the sext is non-negative. That is the case here because the loop induction variable starts at zero and stops before it reaches n (if n is negative, the loop never executes at all). The final change is adding the “nuw” (no unsigned wrap) flag to the instruction that produces %10. We can see that this is safe by observing that (1) the induction variable is always increasing and (2) that if a variable starts at zero and increases, it would become undefined by passing the sign wraparound boundary next to INT_MAX before it reaches the unsigned wraparound boundary next to UINT_MAX. This flag could be used to justify subsequent optimizations.
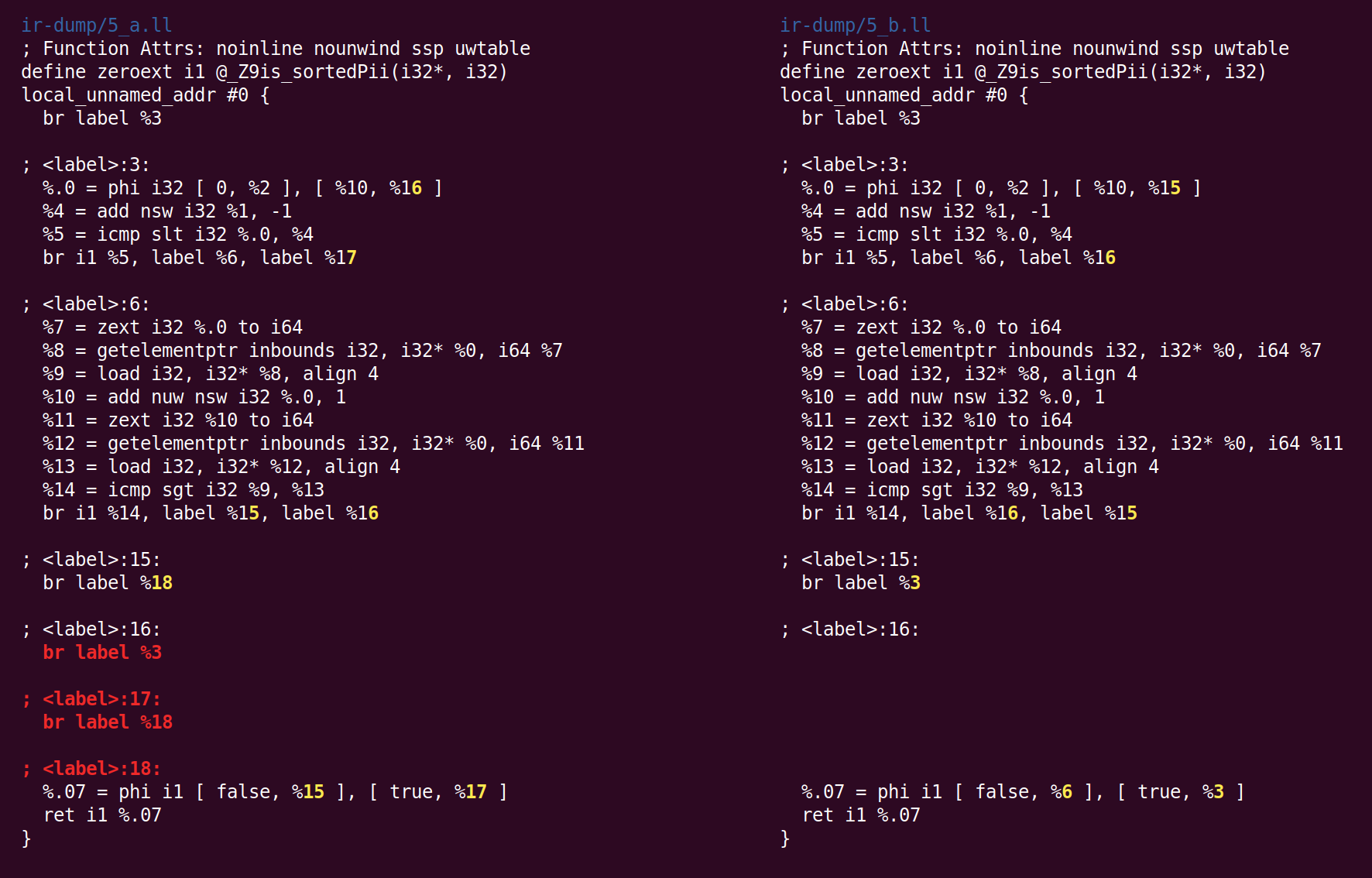
Next, SimplifyCFG runs for a second time, removing two empty basic blocks:
“Deduce function attributes” annotates the function further:
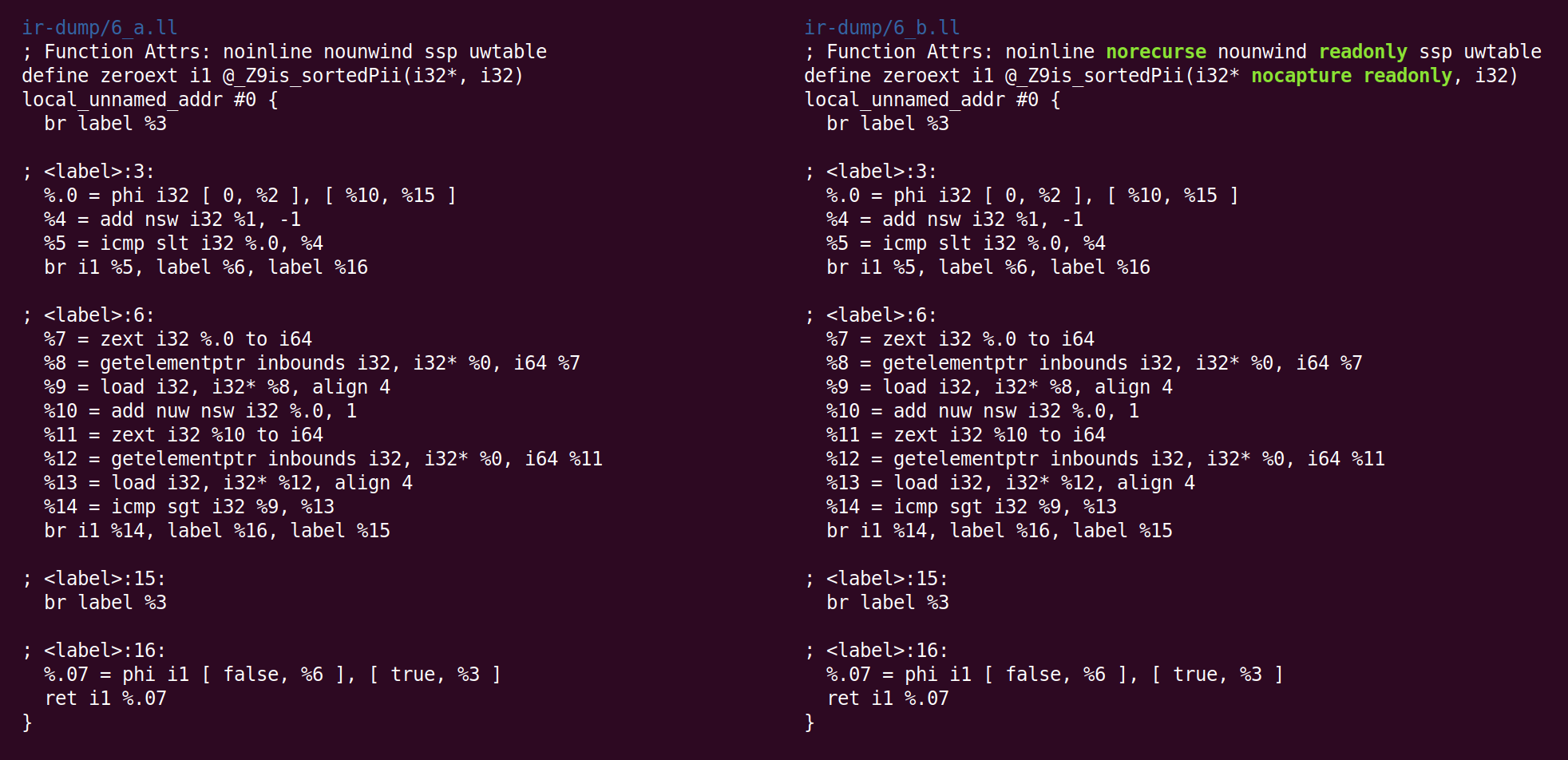
“Norecurse” means that the function is not involved in any recursive loop and a “readonly” function does not mutate global state. A “nocapture” parameter is not saved anywhere after its function returns and a “readonly” parameter refers to storage not modified by the function. Also see the full set of function attributes and the full set of parameter attributes.
Next, “rotate loops” moves code around in an attempt to improve conditions for subsequent optimizations:
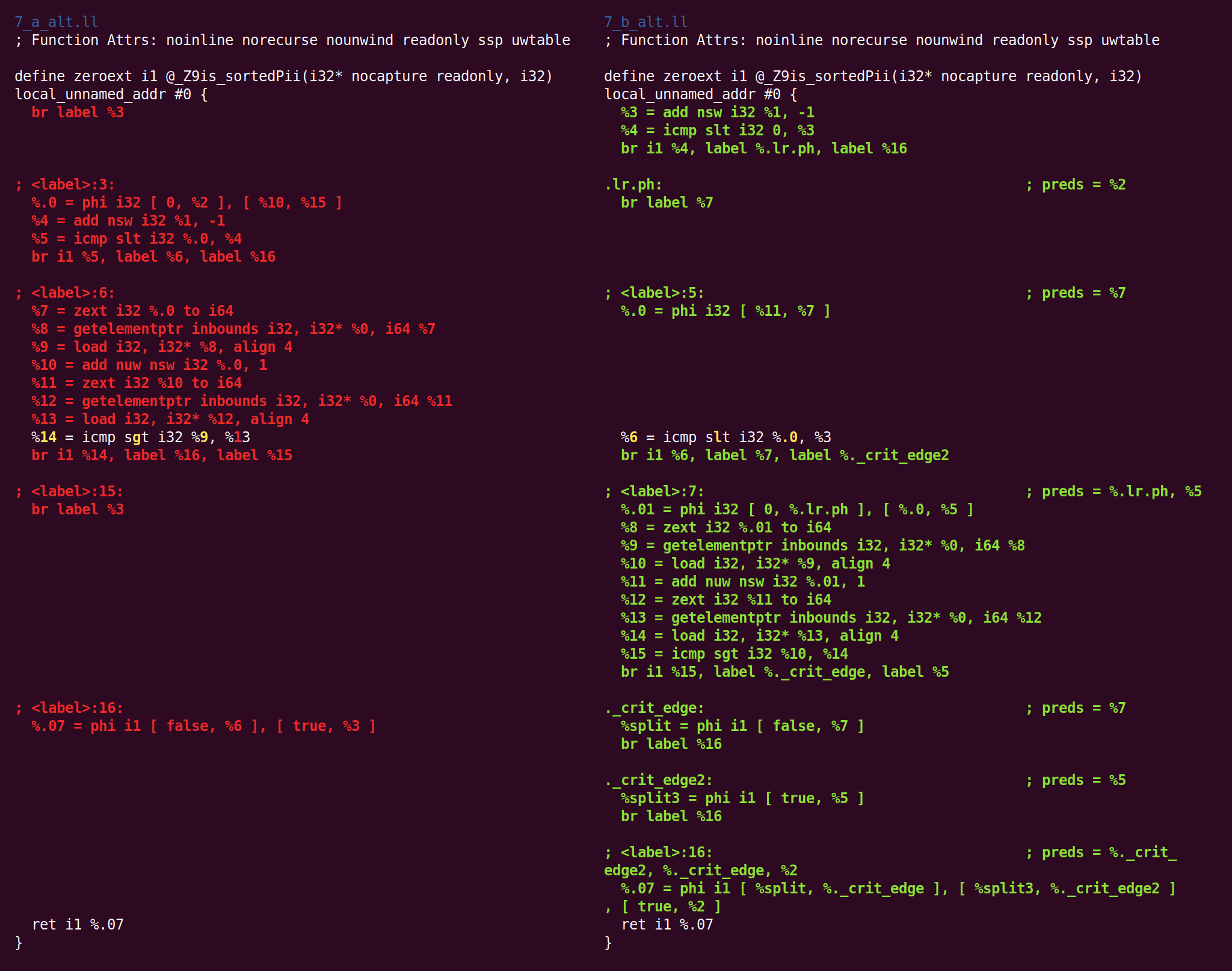
Although this diff looks a bit alarming, there’s not all that much happening. We can see what happened more readily by asking LLVM to draw the control flow graph before and after loop rotation. Here are the before (left) and after (right) views:
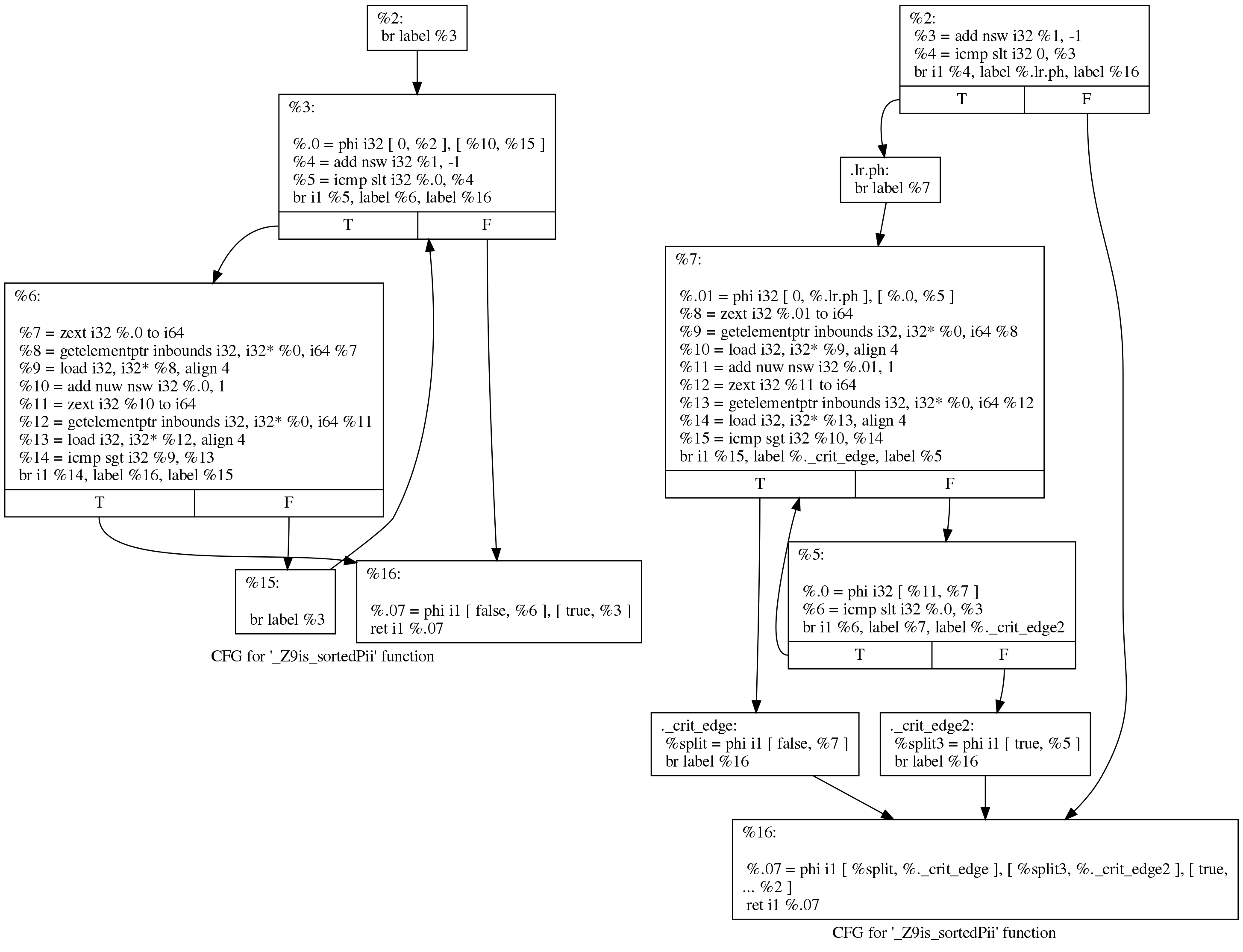
The original code still matches the loop structure emitted by Clang:
initializer
goto COND
COND:
if (condition)
goto BODY
else
goto EXIT
BODY:
body
modifier
goto COND
EXIT:
Whereas the rotated loop looks like this:
initializer
if (condition)
goto BODY
else
goto EXIT
BODY:
body
modifier
if (condition)
goto BODY
else
goto EXIT
EXIT:
(Corrected as suggested by Johannes Doerfert below– thanks!)
The point of loop rotation is to remove one branch and to enable subsequent optimizations. I did not find a better description of this transformation on the web (the paper that appears to have introduced the term doesn’t seem all that relevant).
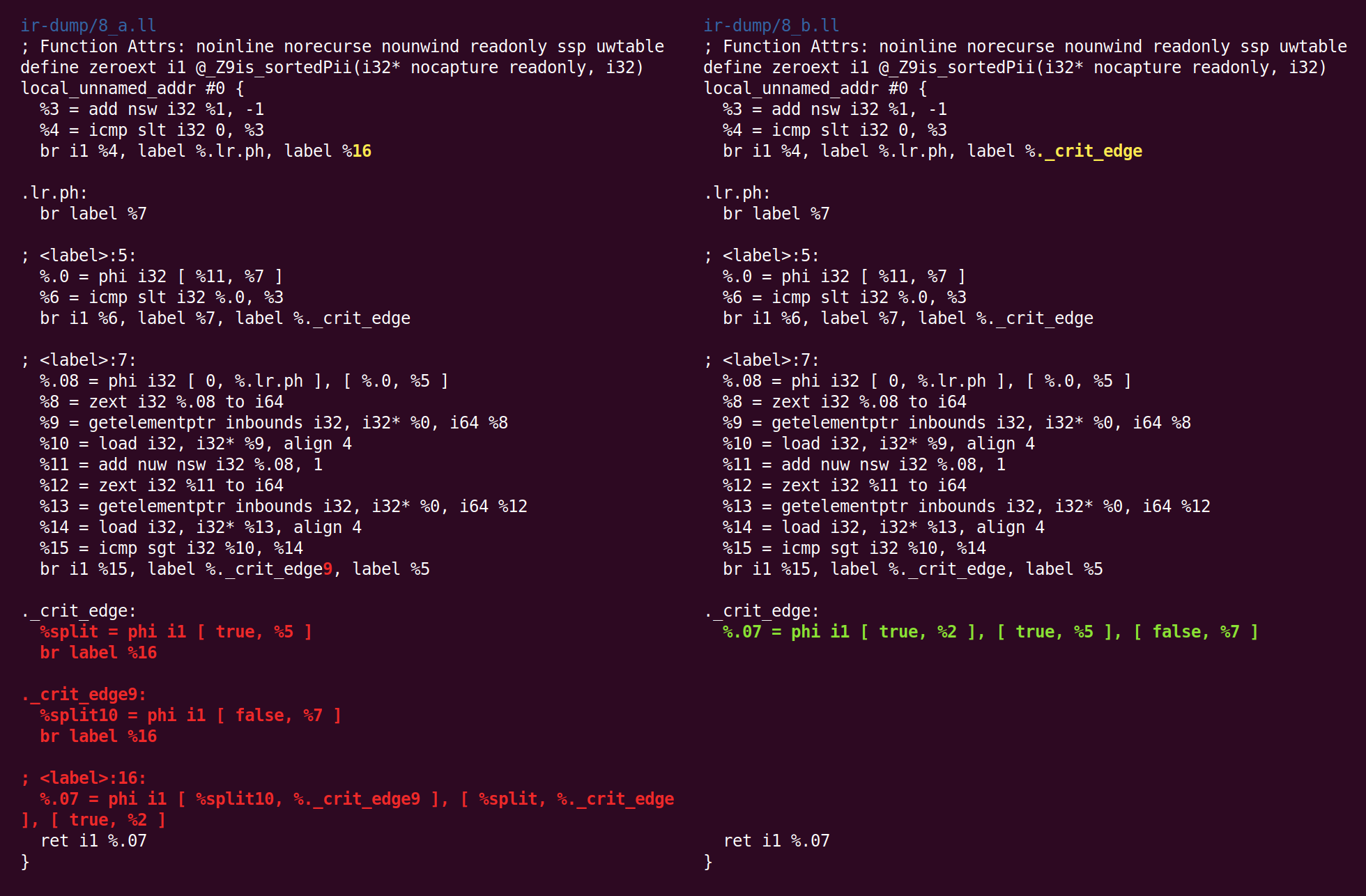
CFG simplification folds away the two basic blocks that contain only degenerate (single-input) phi nodes:
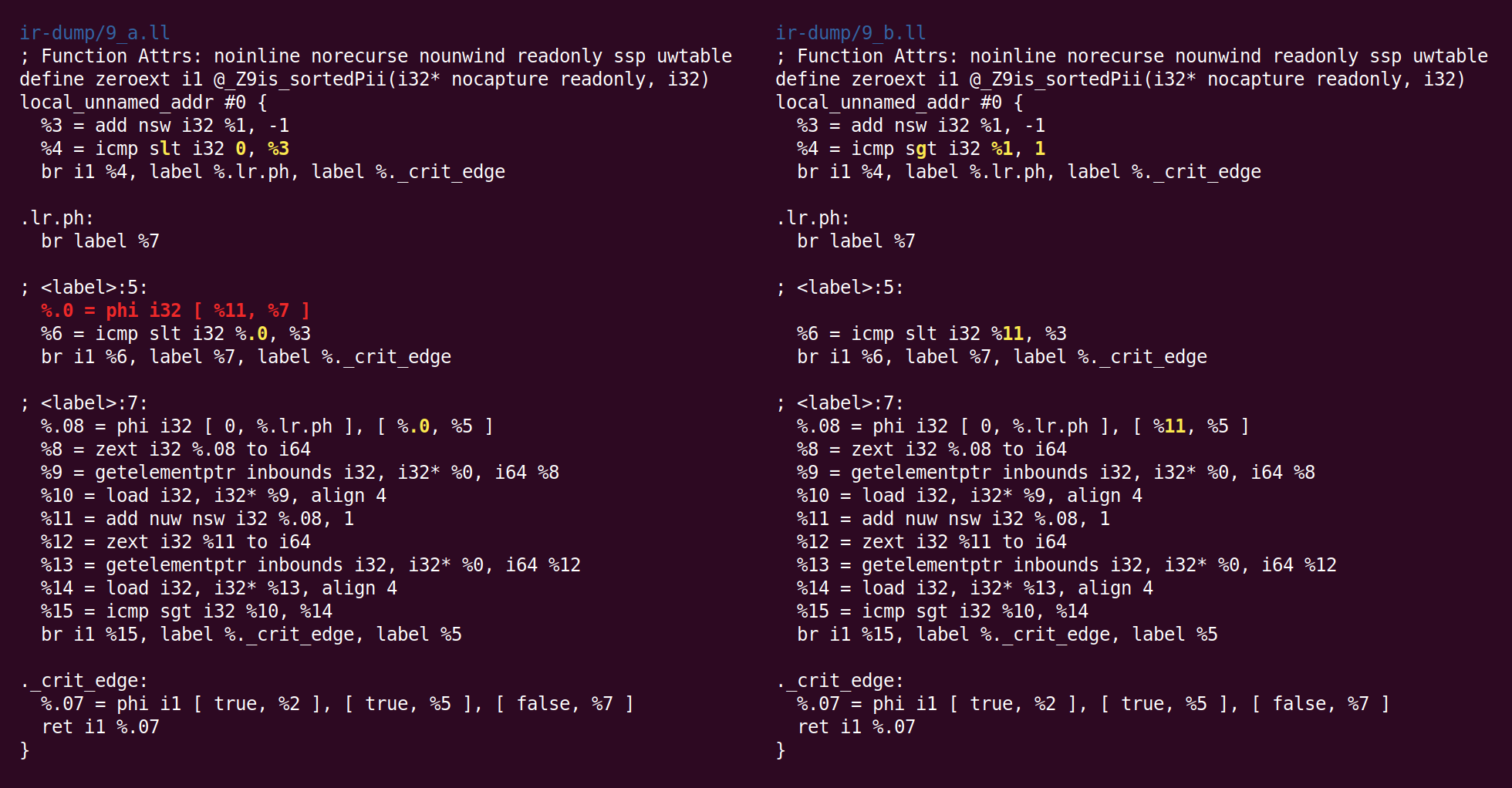
The instruction combiner rewrites “%4 = 0 s< (%1 - 1)" as "%4 = %1 s> 1″, this kind of thing is useful because it reduces the length of a dependency chain and may also create dead instructions (see the patch making this happen). This pass also eliminates another trivial phi node that was added during loop rotation:
Next, “canonicalize natural loops” runs, it self-describes as:
Loop pre-header insertion guarantees that there is a single, non-critical entry edge from outside of the loop to the loop header. This simplifies a number of analyses and transformations, such as LICM.
Loop exit-block insertion guarantees that all exit blocks from the loop (blocks which are outside of the loop that have predecessors inside of the loop) only have predecessors from inside of the loop (and are thus dominated by the loop header). This simplifies transformations such as store-sinking that are built into LICM.
This pass also guarantees that loops will have exactly one backedge.
Indirectbr instructions introduce several complications. If the loop contains or is entered by an indirectbr instruction, it may not be possible to transform the loop and make these guarantees. Client code should check that these conditions are true before relying on them.
Note that the simplifycfg pass will clean up blocks which are split out but end up being unnecessary, so usage of this pass should not pessimize generated code.
This pass obviously modifies the CFG, but updates loop information and dominator information.
Here we can see loop exit-block insertion happen:

Next up is “induction variable simplification“:
If the trip count of a loop is computable, this pass also makes the following changes:
- The exit condition for the loop is canonicalized to compare the induction value against the exit value. This turns loops like: ‘for (i = 7; i*i < 1000; ++i)' into 'for (i = 0; i != 25; ++i)'
- Any use outside of the loop of an expression derived from the indvar is changed to compute the derived value outside of the loop, eliminating the dependence on the exit value of the induction variable. If the only purpose of the loop is to compute the exit value of some derived expression, this transformation will make the loop dead.
The effect of this pass here is simply to rewrite the 32-bit induction variable as 64 bits:

I don’t know why the zext — previously canonicalized from a sext — is turned back into a sext.
Now “global value numbering” performs a very clever optimization. Showing this one off is basically the entire reason that I decided to write this blog post. See if you can figure it out just by reading the diff:
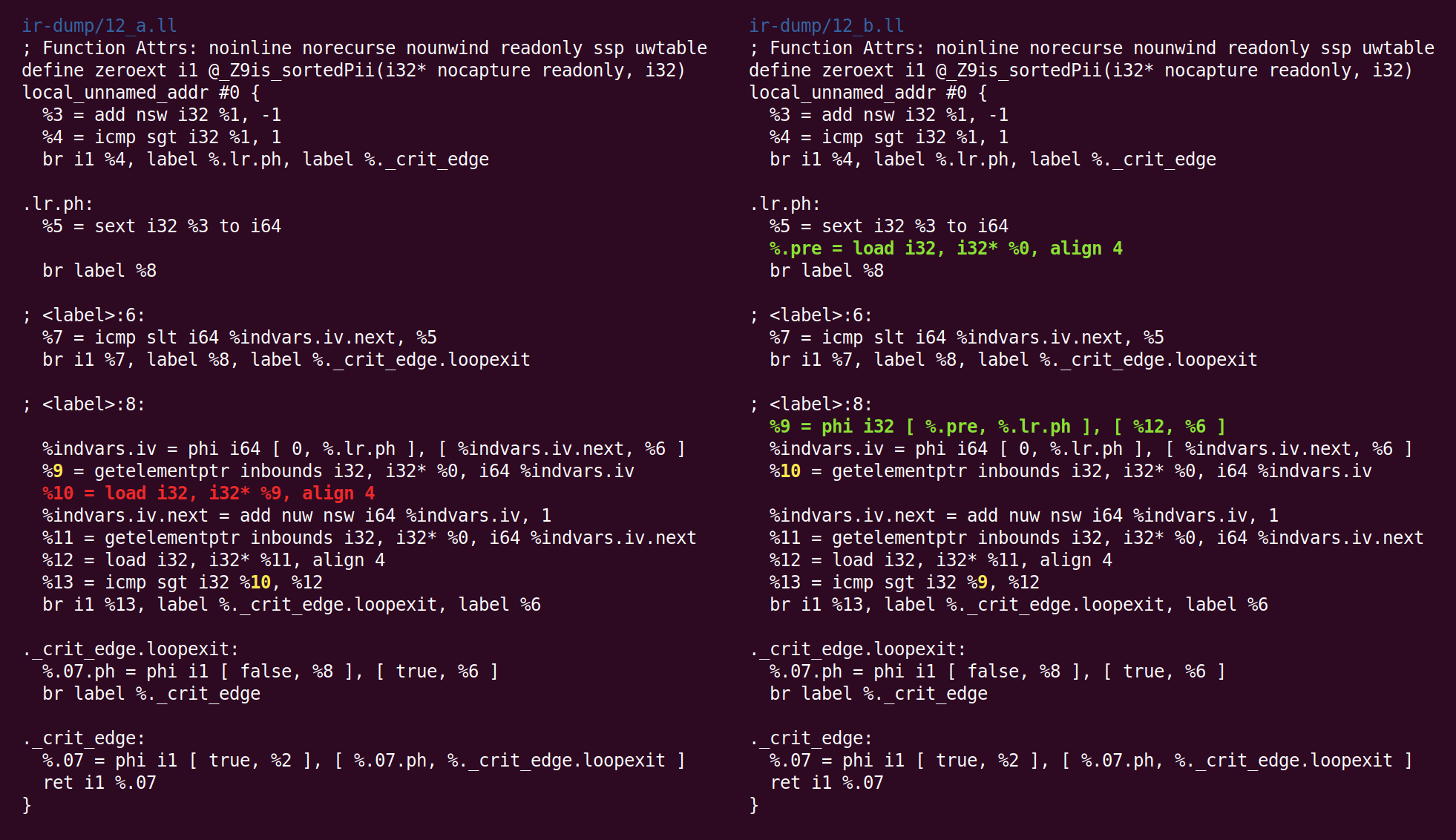
Got it? Ok, the two loads in the loop on the left correspond to a[i] and a[i + 1]. Here GVN has figured out that loading a[i] is unnecessary because a[i + 1] from one loop iteration can be forwarded to the next iteration as a[i]. This one simple trick halves the number of loads issued by this function. Both LLVM and GCC only got this transformation recently.
You might be asking yourself if this trick still works if we compare a[i] against a[i + 2]. It turns out that LLVM is unwilling or unable to do this, but GCC is willing to throw up to four registers at this problem.
Now “bit-tracking dead code elimination” runs:
But it turns out the extra cleverness isn’t needed since the only dead code is a GEP, and it is trivially dead (GVN removed the load that previously used the address that it computes):
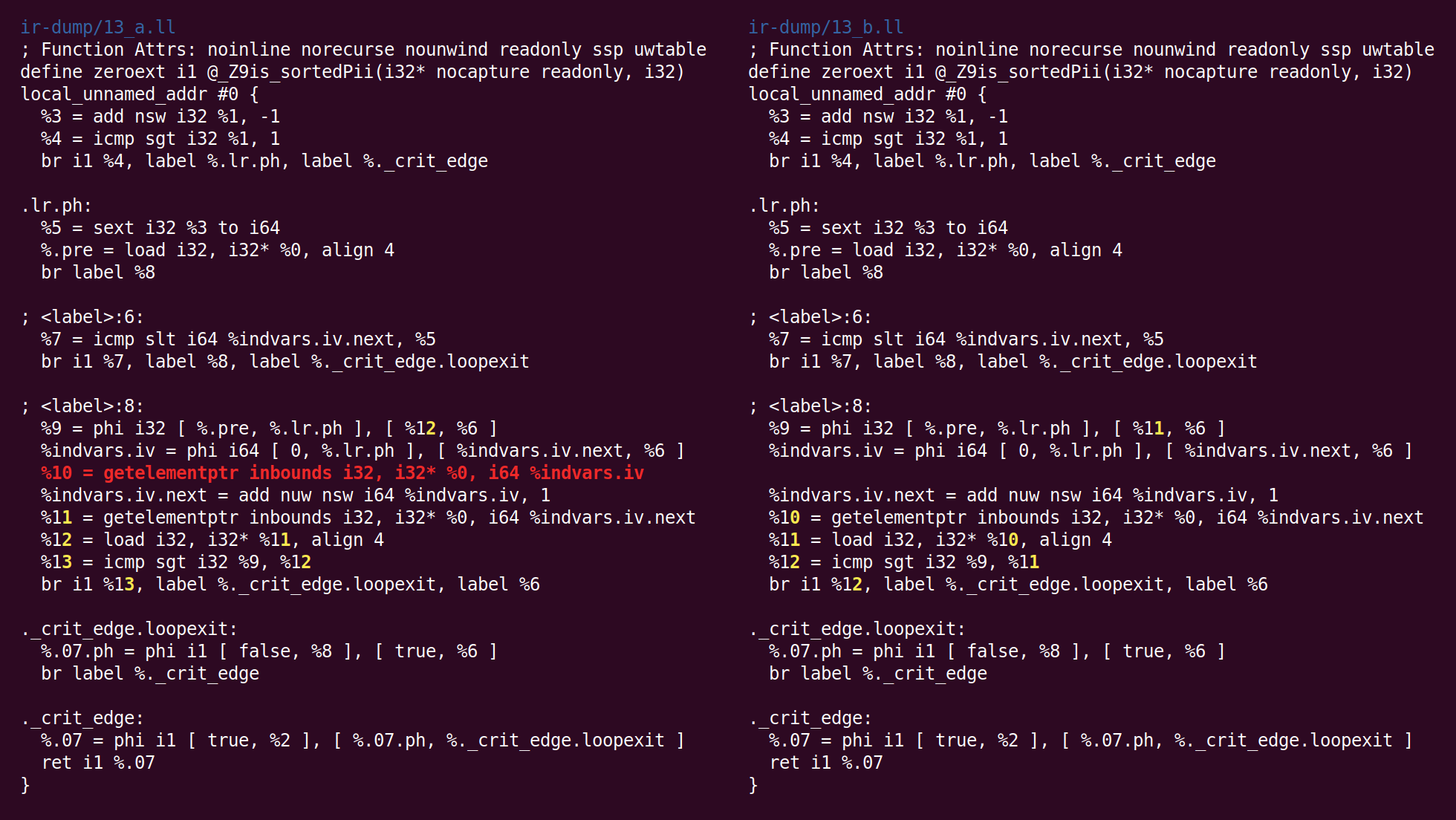
Now the instruction combiner sinks an add into a different basic block. The rationale behind putting this transformation into InstCombine is not clear to me; perhaps there just wasn’t a more obvious place to do this one:

Now things get a tiny bit weird, “jump threading” undoes what “canonicalize natural loops” did earlier:

Then we canonicalize it back:
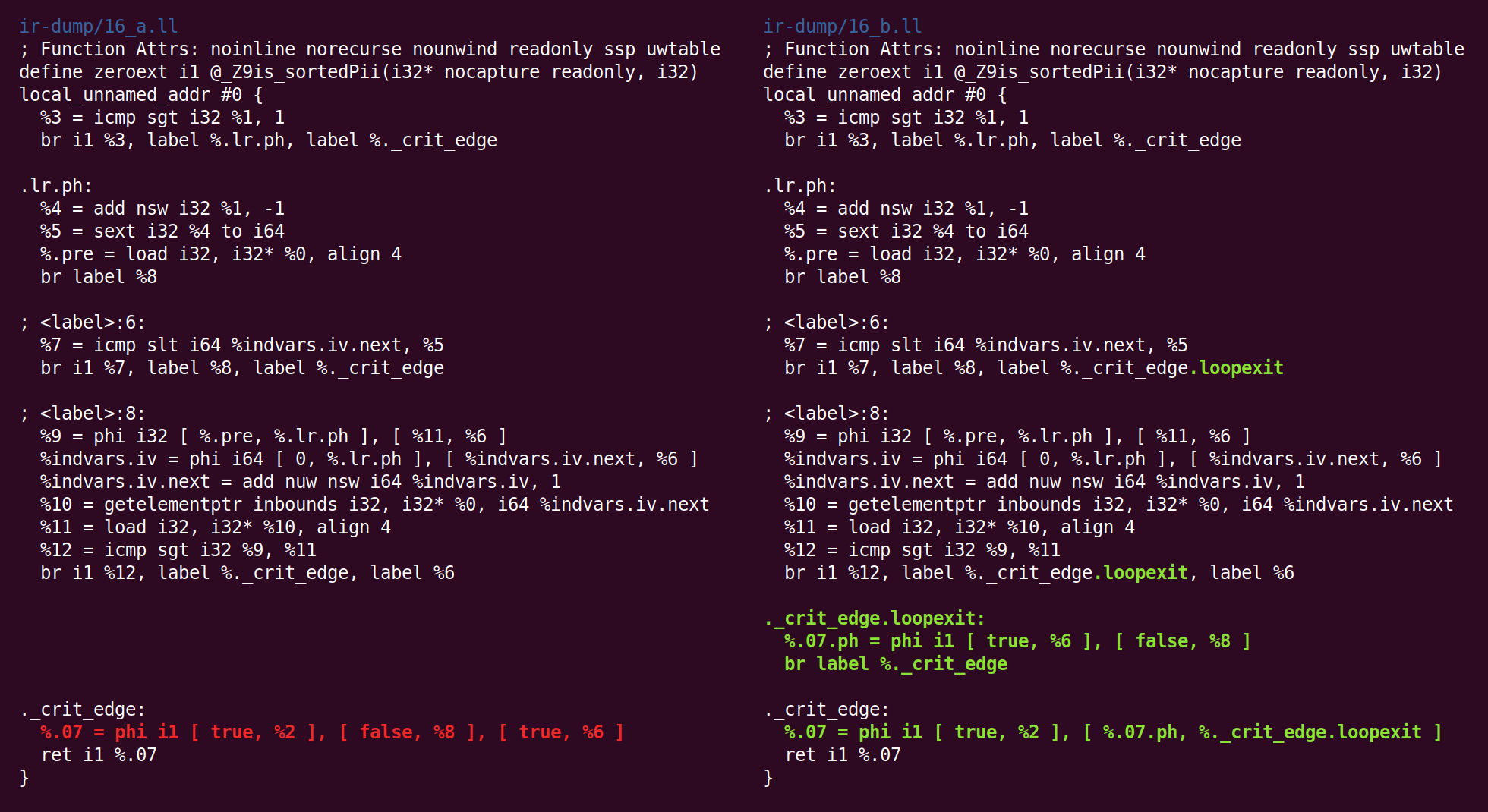
And CFG simplification flips it the other way:
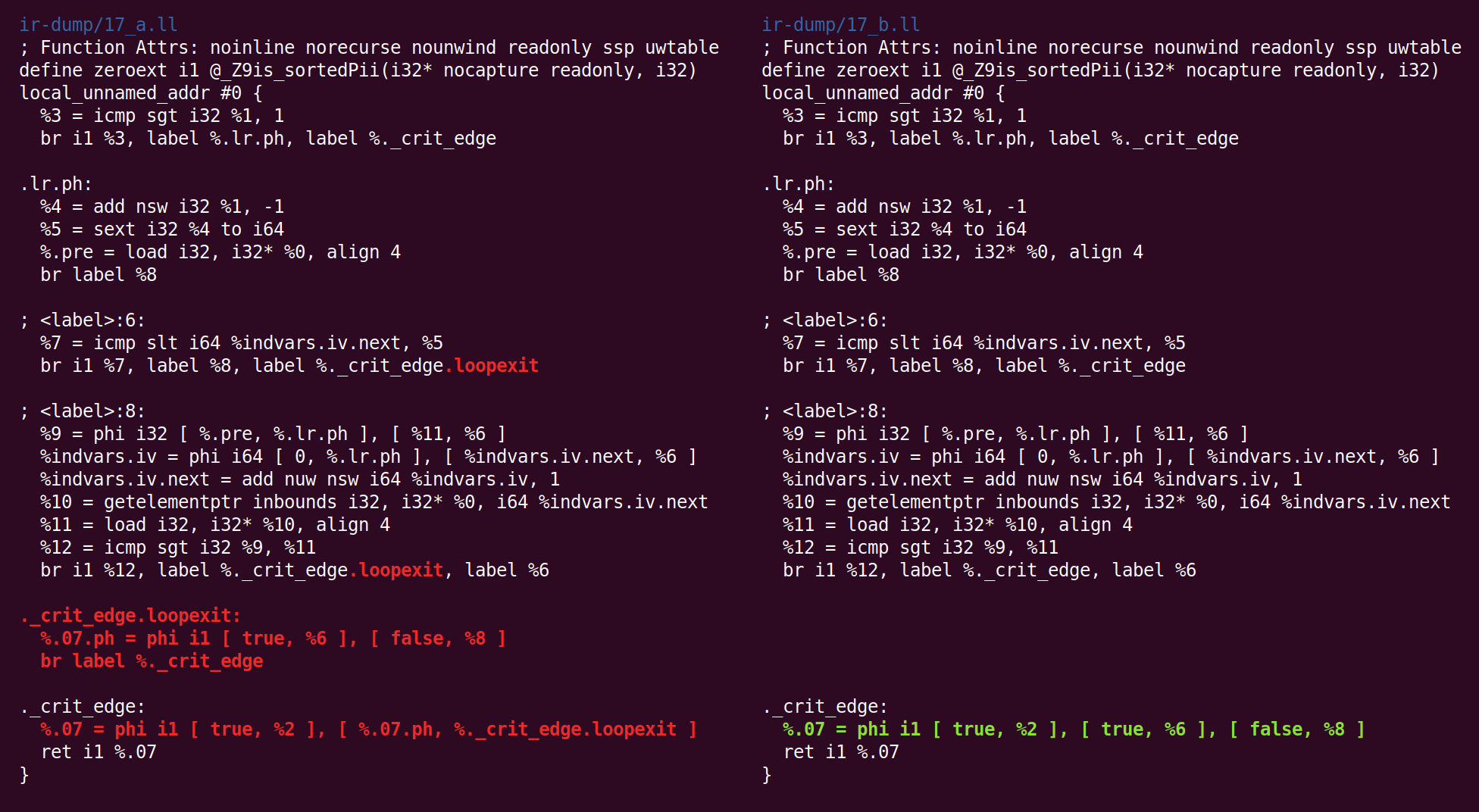
And back:
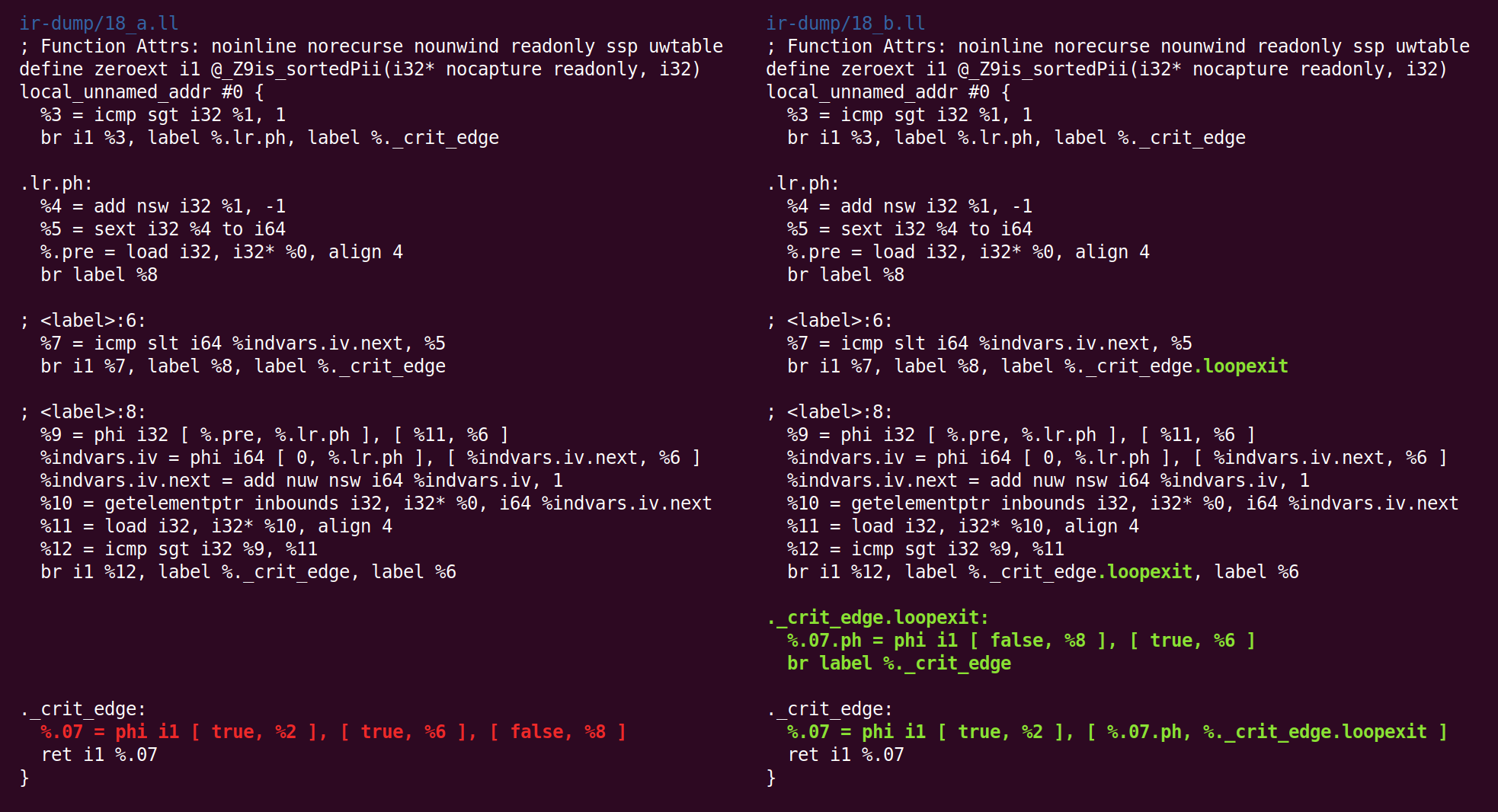
And forth:
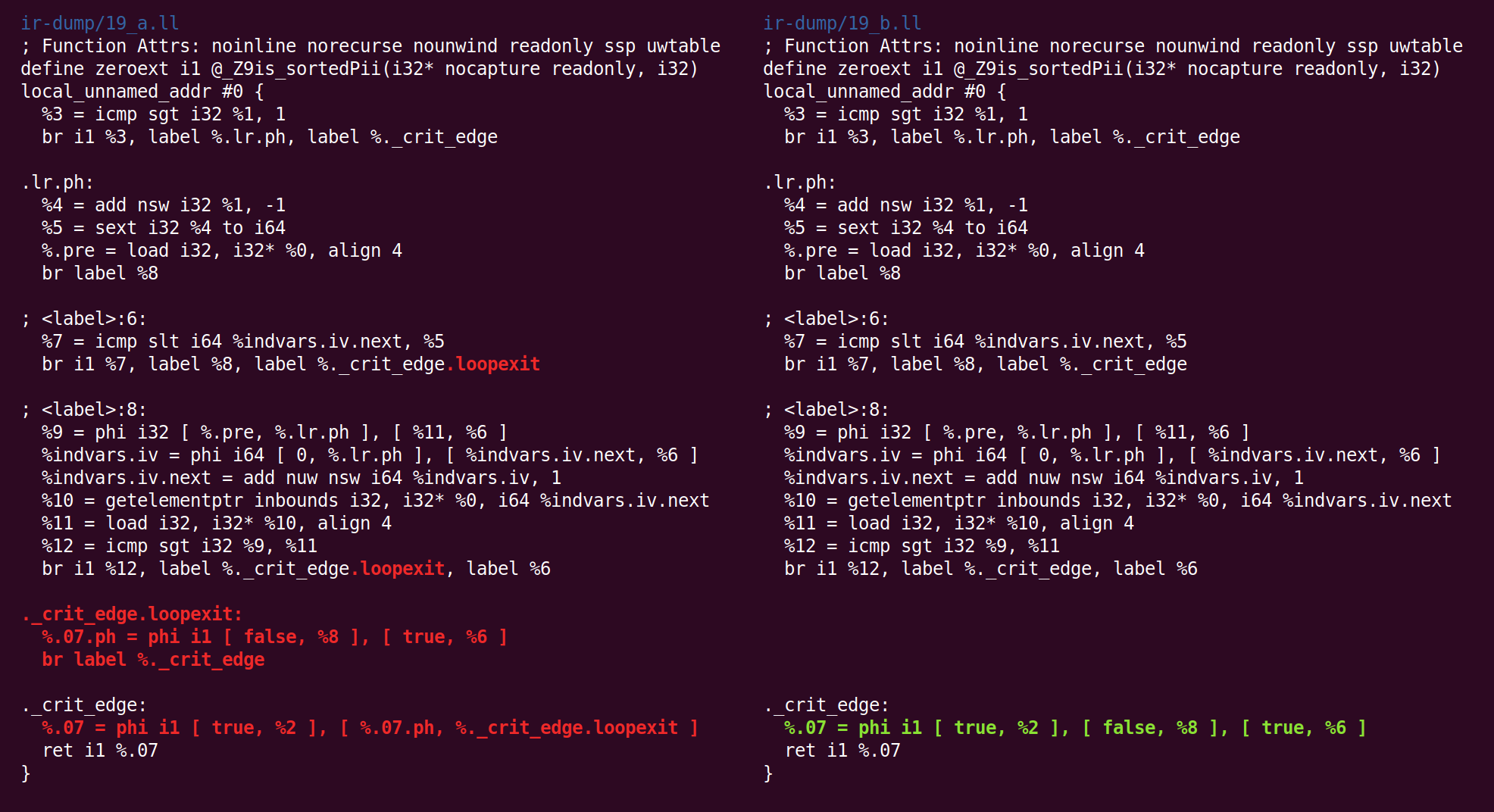
And back:
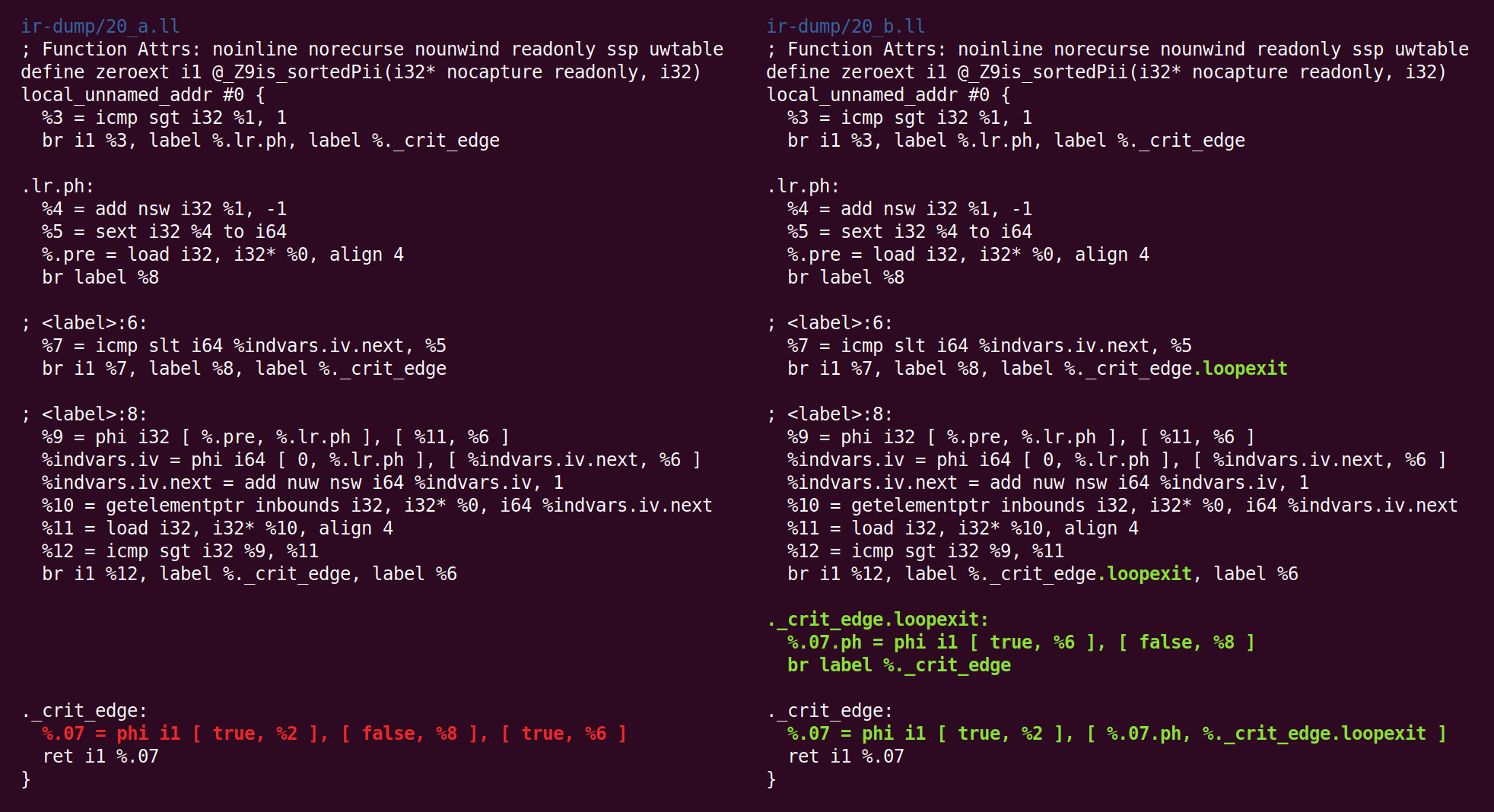
And forth:
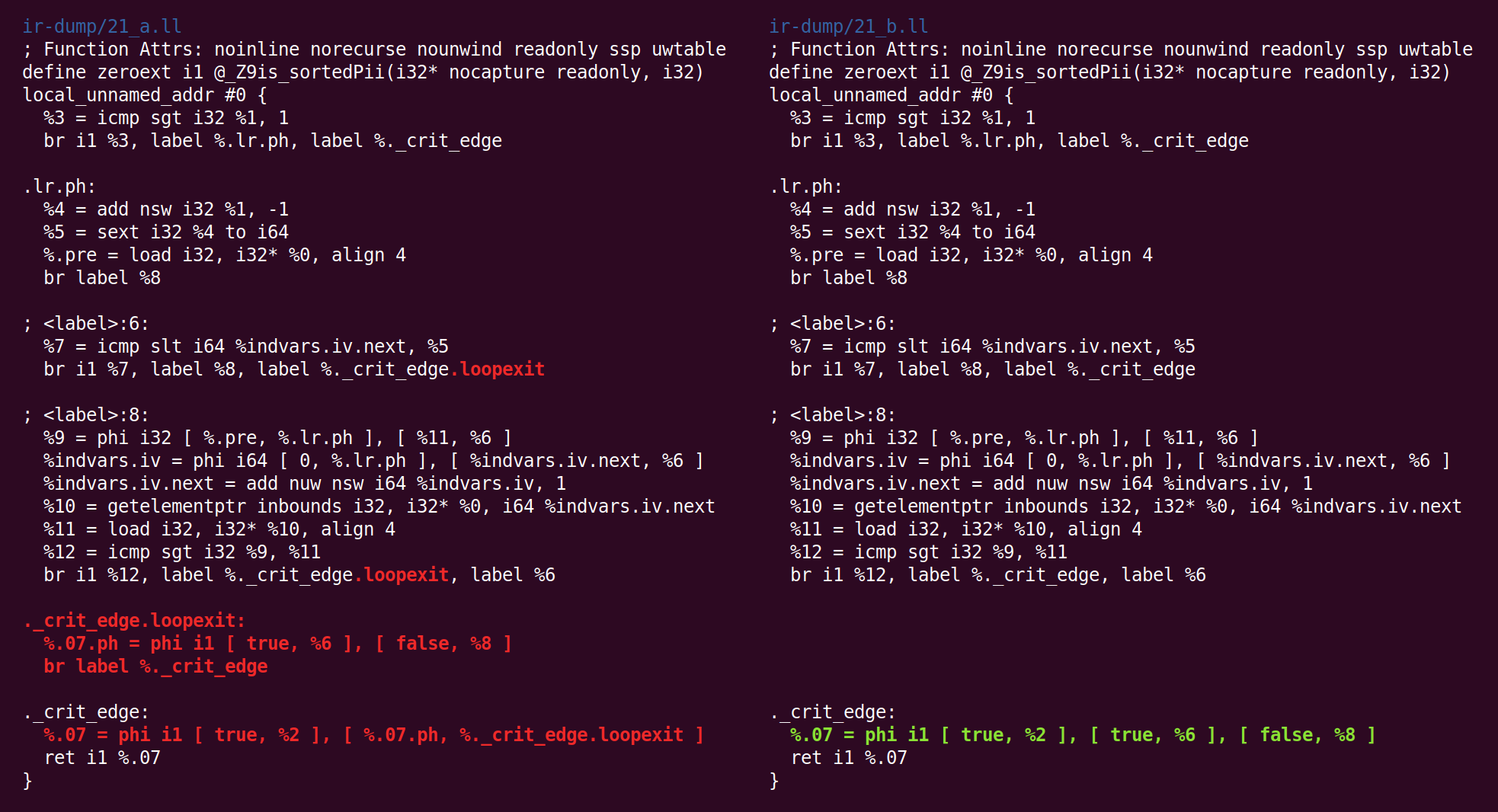
Whew, we’re finally done with the middle end! The code at the right is what gets passed to (in this case) the x86-64 backend.
You might be wondering if the oscillating behavior towards the end of the pass pipeline is the result of a compiler bug, but keep in mind that this function is really, really simple and there were a whole bunch of passes mixed in with the flipping and flopping, but I didn’t mention them because they didn’t make any changes to the code. As far as the second half of the middle end optimization pipeline goes, we’re basically looking at a degenerate execution here.
Acknowledgments: Some students in my Advanced Compilers class this fall provided feedback on a draft of this post (I also used this material as an assignment). I ran across the function used here in this excellent set of lecture notes about loop optimizations.
10 responses to “How LLVM Optimizes a Function”
This is very nice summary of IR Passes. I found “InstCombine” pass to be easier to start with to understand the code flow in LLVM IR Pass. Maybe the beginners can start with that first.
> This one simple trick halves the number of loads issued by this function. Both LLVM and GCC only got this transformation recently.
Interestingly, GCC had the capability to do that for quite a while, just not with GVN, but with the “predictive commoning” pass designed specifically for that purpose (hence the ability to carry loads over more than one iteration).
On this particular example though, it was not working as intended, because an earlier pass designed to transform the loop into suitable form (“loop header copying”, similar to loop rotation in the article) was copying too much, effectively duplicating one iteration of the loop in its preheader.
Once header copying was throttled down (GCC bug 85275), predictive commoning was able to do its job.
Great article! We need more of these and we should start to link them on the LLVM webpage (if you haven’t already).
One small comment I have concerns loop rotation. First, the rotated loop CFG should be:
initializer
if (condition)
goto BODY
else
goto EXIT
BODY:
body
modifier
if (condition)
goto BODY
else
goto EXIT
EXIT:
which is different because now, the rotated loop requires one less branch compared to the original loop. While that is already a nice achievement,
the rotated loop exposes other optimization opportunities. If we can prove
the first guard to be always true, thus the loop to be always executed, we
can reuse values defined in the loop without the need for a phi in the loop exit node. This is beneficial since the fact that the loop is always executed is now
encoded in IR. Otherwise, we would later analyze the loop multiple times to determine that we’ll never see the initial value (which flows into the loop) but always on defined in the loop. [This is hard to explain without an example, I hope it makes some sense.] Finally, the patch you refer to seems to have never made it in. If that is true, maybe it is a bit misleading.
As I mentioned at my talk at EMF Camp, I have been dreaming lately that we need this for SMT solvers. Research could then focus on IR passes and things would become a lot more comparable and maybe we could innovate a lot faster. Currently, writing a pass into any SMT solver is like writing a pass for gcc in the 2000s. An utter nightmare.
Hi John, very nice post! If you are still looking for references about loop rotation, you can use the wiki entry on Loop Inversion (https://en.wikipedia.org/wiki/Loop_inversion). It seems to me that both names denote the same general optimization that tries to make room for hoisting code outside loops (and it sometimes save the goto in the conditional, depending on how the compiler linearizes the basic blocks).
Nice write up!
Thanks Alexander, I hadn’t heard this history!
Johannes, thanks for the correction, I’ve updated the post a bit.
Mate, I agree!
Hello , Can you please explain this in a bit more detail ?
”
Phis are at the core of the SSA representation, and the lack of phis in the code emitted by Clang tells us that Clang emits a trivial kind of SSA where communication between basic blocks is through memory, instead of being through SSA registers.
“