[This piece is coauthored by Yuyou Fan and John Regehr]
Mutation-based fuzzing is based on the idea that new, bug-triggering inputs can often be created by randomly modifying existing, non-bug-triggering inputs. For example, if we wanted to find bugs in a PDF reader, we could grab a bunch of PDF files off the web, mutate them by flipping a few bits or something, and feed the resulting mutants into our fuzzing target and wait for it to crash or otherwise malfunction.
To exploit this idea for fuzzing LLVM optimization passes, we can plug existing LLVM IR files such as those found in LLVM’s unit test suite into a workflow like this one:
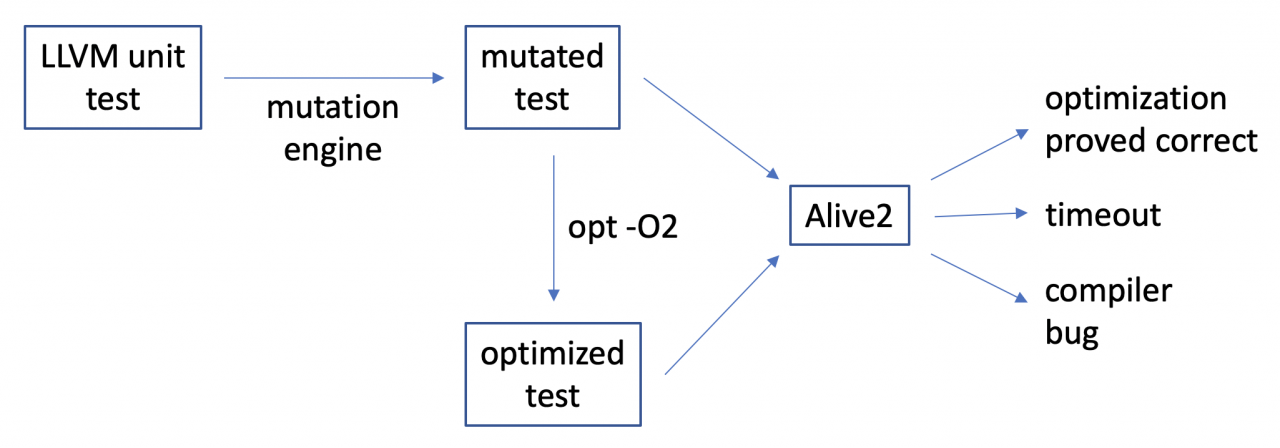
In other words, we create a fresh test case using mutation, optimize it, and then we use our formal methods tool Alive2 to either prove that the optimization was correct, or prove that it was buggy. This sort of collaboration between formal and informal methods ends up being powerful and useful!
The first thing we tried out is radamsa, an open source mutation engine. The resulting testing loop worked poorly: the vast majority of mutated tests were either semantically identical to the original test case or else were not valid bitcode files. This isn’t radamsa’s fault: files in LLVM IR (intermediate representation) have strong validity constraints, making it difficult for a tool that is unaware of the file structure to effect meaningful changes. After running for a few days on a fast machine, we did not discover any bugs this way. It’s possible that a different domain-independent mutation engine, such as the one found in AFL, would work better, but this doesn’t seem likely and we didn’t pursue it. (Related, C-Reduce does a poor job reducing LLVM IR, whereas the domain-specific llvm-reduce is quite good.)
Next, we wrote a custom mutator for LLVM IR that always generates valid output. To do this, we used existing APIs for things like replacing all uses of an SSA value and computing the SSA dominator tree, in order to avoid generating outputs that violate IR invariants. Mutations that we can do include:
- replacing an instruction with a different one, for example changing left-shift to subtraction
- permuting an instruction’s operands
- toggling flags attached to instructions such as the “exact” flag on division and the “no unsigned wrap” flag on addition and subtraction
- toggling various attributes attached to functions and function parameters
- changing constant values
- adding a randomly generated instruction with randomly chosen inputs, and then replacing an SSA use with the value produced by this instruction
- inserting a call to a function and then inlining its body using the LLVM inliner
Of course you can probably think of additional ways to mutate a function — and hopefully we’ll get around to implementing those sooner or later. But this seems like a reasonable start.
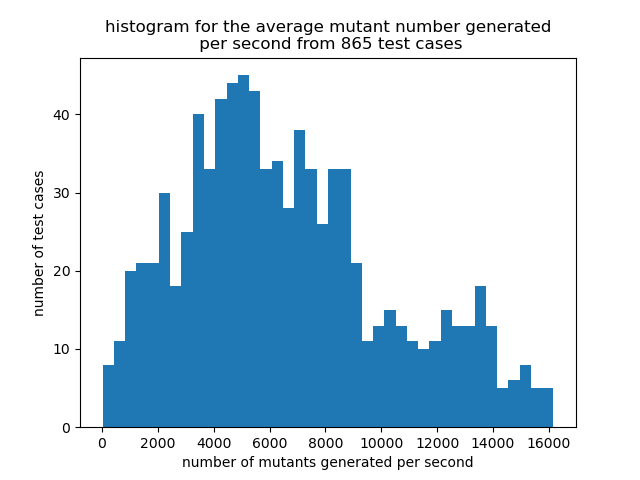
Our original, radamsa-based fuzzing loop was structured as a collection of processes interacting through the filesystem. That setup incurred a lot of overhead due to repeated fork/exec, parse/print, etc. The new fuzzing loop with our custom mutator lives in a single unix process and has much higher fuzzing throughput. Basically, we invoke a program called alive-mutate on an IR file and let it know how long to run, and then it tests as many mutants as possible before reaching its time limit. If we want to fuzz each of the ~7000 unit tests in the llvm/test/Transforms directory for 10 minutes, this takes about 36 hours on a 32-core machine. We can create a mutant, optimize it, and prove the optimization correct up to about 16,000 times per second, though the loop can be much slower than this when the file is large or when Z3 has a hard time finding a proof. Here’s what the throughput looks like for some files randomly chosen from the LLVM unit test suite:
Let’s look at an example of how mutation works. We’ll start with this function that is found in the LLVM unit tests:
declare i8* @bar(i8*) readonly nounwind
define internal i8* @callee_with_explicit_control_flow(i8* %p) alwaysinline {
%r = call i8* @bar(i8* %p)
%cond = icmp ne i8* %r, null
br i1 %cond, label %ret, label %orig
ret:
ret i8* %r
orig:
ret i8* %p
}
Here you can see how the LLVM optimizer transforms this code: it replaces the control flow with a ternary “select” instruction. Alive2 agrees with LLVM that that optimization is correct.
Now we invoke alive-mutate, asking it to run for 60 seconds and to dump its results into a directory called “output”:
$ alive-mutate -t 60 test.ll output Unsound found! at 124th copies Unsound found! at 140th copies Unsound found! at 182th copies Unsound found! at 269th copies Unsound found! at 557th copies program ended Summary: 818 correct transformations 5 incorrect transformations 0 failed-to-prove transformations 0 Alive2 errors $
This is telling us that Alive2 believes that 818 mutants were optimized correctly by LLVM and that five were optimized incorrectly. Here’s one of them:
declare i8* @bar(i8*)
define internal i8* @callee_with_explicit_control_flow(i8* %p) {
%r = call i8* @bar(i8* %p)
%cond = icmp ne i8* %r, %p
br i1 %cond, label %ret, label %orig
ret:
ret i8* %r
orig:
ret i8* %p
}
What changed here? Just the second operand of the icmp instruction, which is testing two pointers for inequality. But now the optimizer does something different, it rewrites the function to this:
define i8* @callee_with_explicit_control_flow(i8* %p) {
%r = call i8* @bar(i8* %p)
ret i8* %r
}
Before we look at why this is incorrect, let’s make sure we understand what the optimizer is thinking. The mutated function compares two pointers for inequality; if they are unequal it returns %r, if they are equal it returns %p. But if they’re equal, the optimizer reasons that returning %r is just as good as returning %p. In practice it’s a bit more complicated than that, a few different passes are involved, but the details aren’t all that important. The upshot is that this transformation is perfectly OK when performed on integer code, but it is wrong for pointers because pointers carry provenance, and two arbitrary pointers cannot be interchanged just because they compare as equal. Alive2 will even try to explain this to us if we read its counterexample carefully. What it is telling us is that %p has offset 2 into a memory block of size 0 and that %r has offset 0 into a memory block of size 1. This explains how the pointers can compare as equal: %p is out-of-bounds (perfectly legal in LLVM as long as we don’t dereference it) and happens to refer to the same location as %r. But these are not interchangeable! In a different situation, this optimization would end up replacing an in-bounds pointer with an out-of-bounds pointer, which is not good; followed by other optimizations, this sort of thing could cascade into an end-to-end miscompile. Alas, this is a long-standing LLVM defect that is known to the community and there’s no point reporting it. There’s a bit of a broader lesson about formal methods here, which is that verification is just one small part of the larger enterprise of creating high-quality software. Happily, other bugs that we find and report do get fixed.
Here are some bugs we found using alive-mutate:
- https://bugs.llvm.org/show_bug.cgi?id=51351
- https://bugs.llvm.org/show_bug.cgi?id=51618
- https://github.com/llvm/llvm-project/issues/53252
- https://github.com/llvm/llvm-project/issues/53218
- https://github.com/llvm/llvm-project/issues/55003
- https://github.com/llvm/llvm-project/issues/55178
- https://github.com/llvm/llvm-project/issues/55201
- https://github.com/llvm/llvm-project/issues/55129
- https://github.com/llvm/llvm-project/issues/55271
- https://github.com/llvm/llvm-project/issues/55284
- https://github.com/llvm/llvm-project/issues/55287
- https://github.com/llvm/llvm-project/issues/55296
- https://github.com/llvm/llvm-project/issues/55342
- https://github.com/llvm/llvm-project/issues/55484
- https://github.com/llvm/llvm-project/issues/55490
- https://github.com/llvm/llvm-project/issues/52884
In summary, alive-mutate’s hybrid fuzzing and formal verification approach works nicely and is also intellectually satisfying: we push the formal methods aspect as far as it can go, and then back off to randomized methods to explore individual cases in situations where we can’t yet formally reason about many cases at once.
So where’s this work going? We want to deploy it in two ways. First, we should have a few spare machines that just build an LLVM every day and then fuzz it, reporting any new bugs as they show up. The best time to discover a bug is before it gets pushed to the repo, but the second best time is immediately after it lands, while the logic is still fresh in someone’s mind. This kind of fuzzing offers a good chance to make that happen. Second, we want to use translation validation beyond bug-finding: we should use tools like Alive2 to monitor the compilation of codes whose correctness we care about, in order to ensure that nothing went wrong along the way. This is far more difficult, but we’re working on it.