If we say that a compiler is buggy, we need to be able to back up that claim with reproducible, compelling, and understandable evidence. Usually, this evidence centers on a test case that triggers the buggy behavior; we’ll say something like “given this test case, compiler A produces an executable that prints 0 whereas compiler B produces an executable that prints 1, therefore there’s a bug.” (In practice compilers A and B are usually different versions or different optimization levels of the same compiler — this doesn’t matter.)
The problem is that when compilers A and B emit code that behaves differently, the divergence can happen for reasons other than compiler bugs:
- the program might rely on undefined behavior (UB) or unspecified behavior,
- the program might read non-constant data from its environment, for example by looking at the clock or at its process id,
- the program might be concurrent and its output influenced by scheduling decisions.
A big part of convincing someone that the compiler is buggy is convincing them that the test program is free of problems such as these. Since concurrency and interactions with the environment are easy to spot, the problem is often undefined behavior. You can find a few examples in my previous post about invalid GCC bug reports.
This post is about partially automating the process of coming up with a small test case for a miscompilation bug. The bug that we’ll be studying shows up when you compile the latest version of GMP, 6.1.1, using Clang+LLVM revision 135022, from about five years ago. The bug itself is irrelevant and long fixed, I’m just using it to illustrate the process.
As a slight digression, I’ll add that out of the 90 versions of LLVM, spanning revisions 90,000-250,000, that I used to compile GMP (in its C-only mode, disabling use of assembly), only those in the 135,000-139,000 range miscompiled GMP 6.1.1, according to its test suite. The GMP web page says:
Most problems with GMP these days are due to problems not in GMP, but with the compiler used for compiling the GMP sources. This is a major concern to the GMP project, since an incorrect computation is an incorrect computation, whether caused by a GMP bug or a compiler bug. We fight this by making the GMP testsuite have great coverage, so that it should catch every possible miscompilation.
This is all well and good but GMP used to contain some integer undefined behaviors and my guess is that some of the apparent miscompilations were actually due to compiler exploitation of these UBs. Finding some evidence one way or the other about this might be a fun project for a student.
Anyway, back to our compiler bug. The process for isolating a test case is:
- Grab a failing unit test.
- Use tis-interpreter to verify that it is free of undefined behavior and anything else that might trigger non-deterministic execution.
- Use C-Reduce to create a minimal program triggering the bug.
This sounds really easy — and it would be if we were working with a tidy little test case generated by Csmith — but real software is messy and there are plenty of complications. Let’s get started. The unit test we’re using is called mpz_lucnum_ui. Here are the 128 C files that are required to run it.
A First Try
We have to choose what exactly to reduce. Usually we want to reduce preprocessed code, but given the painfully slow interestingness test that we have here (almost 40 seconds, argh) this is going to make very slow progress since C-Reduce would need to eliminate a lot of redundant included junk from each of the 128 files. So let’s rather reduce the files without preprocessing and see what happens.
I had to make a few easy changes to get the GMP files to go through tis-interpreter. In an ideal future, the GMP project (and everyone else) will ensure that their unit tests are clean with respect to tis-interpreter.
Finally we’re ready to run the reduction:
$ creduce ./test1.sh *.c
After a few days the reduction finishes, see the results here. 119 of the 128 C files have become empty and the remaining 9 files contain a total of about 5 KB of code. A bit more than 99% of the code has been eliminated. Perhaps surprisingly, C-Reduce has managed to eliminate all conditional compilation directives, but some #defines remain as do a few #includes.
We’ve succeeded in creating a modestly small test case, but it isn’t yet standalone (due to the includes) and really we would like everything to live in a single file. We can kill two birds with one stone by using CIL or Frama-C to merge the C files into a single compilation unit.
$ frama-c -print *.c > merged.c
The merged file isn’t quite buildable — there’s some junk at the top and there’s a minor problem handling a builtin — but this is easy to fix. You can find the result here. Unfortunately, the merged file doesn’t trigger the bug any longer. Either the testcase relied on separate compilation or else Frama-C’s rewriting of the source code perturbed things badly. That’s sort of a bummer. I could easily have omitted this part of the post, but I wanted to show the whole process here, including missteps.
A Second Try
This time we’ll preprocess and merge the 128 files first, and reduce second. Again, some manual patching was necessary since the merger doesn’t quite work. The result is an 800 KB compilation unit.
Again, the reduction goes slowly:
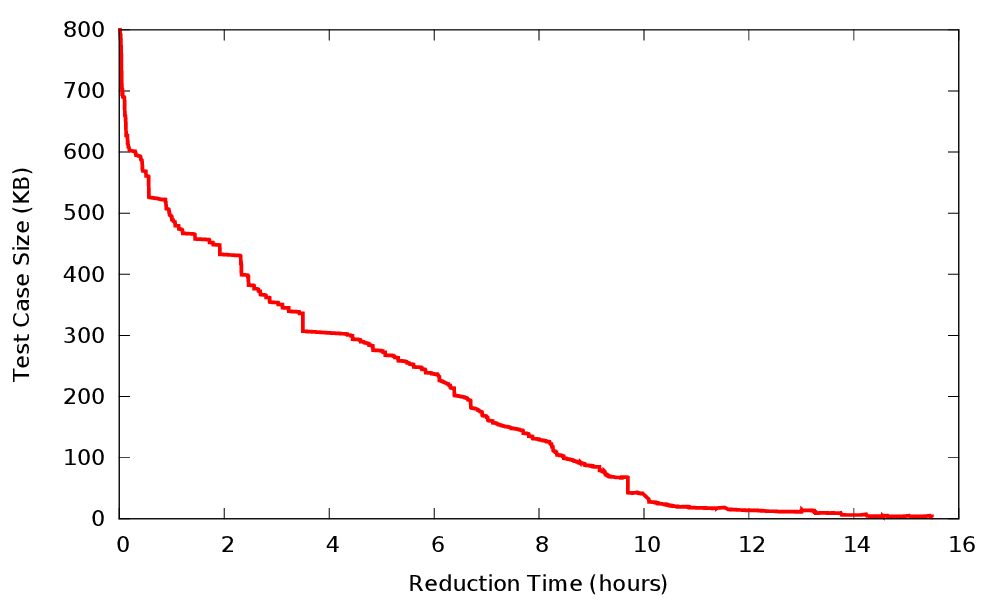
The final result is a bit less than 4 KB. It’s still too big to be easily understood. Since we’ve run up against the limits of our tooling, further reduction will have to be by hand. Since I’m not actually going to report this long-ago-fixed bug, I didn’t bother with this step. (Back before C-Reduce existed I did a lot of manual testcase reduction and while it was a somewhat satisfying and mindless activity, I ran out of patience for it.) But in any case, 4 KB of self-contained C code is quite manageable.
Is Undefined Behavior Checking Necessary?
Is it really necessary to worry about undefined behavior? In my experience, reducing a miscompilation while disregarding UB is roughly 100% likely to result in a testcase that misbehaves due to UB instead of triggering a compiler bug. Here you can see our interestingness test w/o the UB checking. If we run a reduction using it, the resulting 1 KB testcase (hacked a bit by hand so that we can use tis-interpreter to discover its fatal flaw) misbehaves via an out-of-bounds store:
$ tis-interpreter.sh merged.c
merged.c:53:[kernel] warning: Calling undeclared function cu. Old style K&R code?
[value] Analyzing a complete application starting at main
[value] Computing initial state
merged.c:11:[value] warning: during initialization of variable 'cm', size of type 'struct a []' cannot be
computed (Size of array without number of elements.)
merged.c:11:[kernel] imprecise size for variable cm
[value] Initial state computed
merged.c:51:[kernel] warning: out of bounds write. assert \valid(&cp->b);
stack: main
[value] Stopping at nth alarm
[value] user error: Degeneration occurred:
results are not correct for lines of code that can be reached from the degeneration point.
So we definitely need some sort of UB detection. But do we need something as heavyweight as tis-interpreter? I ran a few reductions using UBSan + ASan (see one of them here) and didn’t have good luck in getting a defined final testcase. The reduction kept introducing issues such as uninitialized storage and function declarators with empty parentheses and incompatible uses of function pointers, all of which can lead to real trouble. Most likely there is a combination of compilers and flags that would have let me run this reduction successfully but I ran out of energy to find it. UBSan and ASan and MSan are excellent but fundamentally they do not add up to a completely reliable UB detector.
Recommendations
More developers should:
- Make sure unit tests go through tis-interpreter. Though not always practical (tis-interpreter doesn’t understand assembly or C++) this has many benefits since tis-interpreter implements very thorough checking. Also, when a change in compiler or compiler options breaks a test case that is clean with respect to tis-interpreter, the compiler can be blamed with high reliability.
- Instead of working around compiler bugs, reduce and report them. This can be a lot of work but tools like tis-interpreter and C-Reduce make it easier and when these bugs get fixed life is better for everyone.
6 responses to “Isolating a Free-Range Miscompilation”
I think usually starting by reducing the whole multi-file compiler input at once is overkill or not practical (waiting multiple days or even hours should not be required). In cases like this (works on version A, fails on version B, or e.g. works with CFLAGS A, fails with CFLAGS B), one can start by bisecting the input set by compiler version used, so after 7 steps you’ve reduced the set of original 128 files to just a single file on which switching compiler version makes a difference. And from there the reduction effort can be spent on just that file, usually.
There’s a script that assists with that on the GCC wiki: https://gcc.gnu.org/wiki/Analysing_Large_Testcases
Hi Alexander, I’ll try that script, thanks.
Considering that it’s legal for a C99 compiler to compile everything into `int main(void) {return 117;}`, I don’t understand why GCC continually punts problems simply because it technically is following the standard. Optimizing all programs to simply return 117 would also speed up many programs, and also technically follows the standard.
(Define significant identifier length to be zero, with the exception of one program as per 5.2.4.1 that behaves as-if it just returns 117.)
It could be easier to apply tis-interpreter to existing unit test suites, if it could be run like a traditional C compiler. So instead of taking the C file names and the command line parameters in one go, one could first “compile” the .c files to an intermediate shell script, which could then be run like the program itself.
Hi jpa, I totally agree.
*sigh* if only tis-interpreter supported c++