Hyperthreading (HT) may or may not be a performance win, depending on the workload. I had poor luck with HT in the Pentium 4 era and ever since then have just disabled it in the BIOS on the idea that the kind of software that I typically wait around for—compilers and SMT solvers—is going to get hurt if its L1 and L2 cache resources are halved. This post contains some data about that. I’ll just start off by saying that for at least one combination of CPU and workload, I was wrong.
The benchmark is compilation of LLVM, Clang, and compiler-rt r279412 using Ninja on an Intel i7-5820K, a reasonably modern but by no means new Haswell-E processor with six real cores. The compiler doing the compilation is a Clang 3.8.1 binary from the LLVM web site. The machine is running Ubuntu 14.04 in 64-bit mode.
Full details about the machine are here. As an inexpensive CPU workhorse I think it stands the test of time, though if you were building one today you would double (or more) the RAM and SSD sizes and of course choose newer versions of everything. I’m particularly proud of the crappy fanless video cards I found for these machines.
This is the build configuration command:
cmake -G Ninja -DLLVM_TARGETS_TO_BUILD=host -DLLVM_ENABLE_ASSERTIONS=1 -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_BUILD_TYPE=Release ..
Then, on an otherwise idle machine, I built LLVM five times for each degree of parallelism up to 16, both with and without hyperthreading. Here are the results. Since the variation between runs was very low—a few seconds at worst—I’m not worrying about statistics.
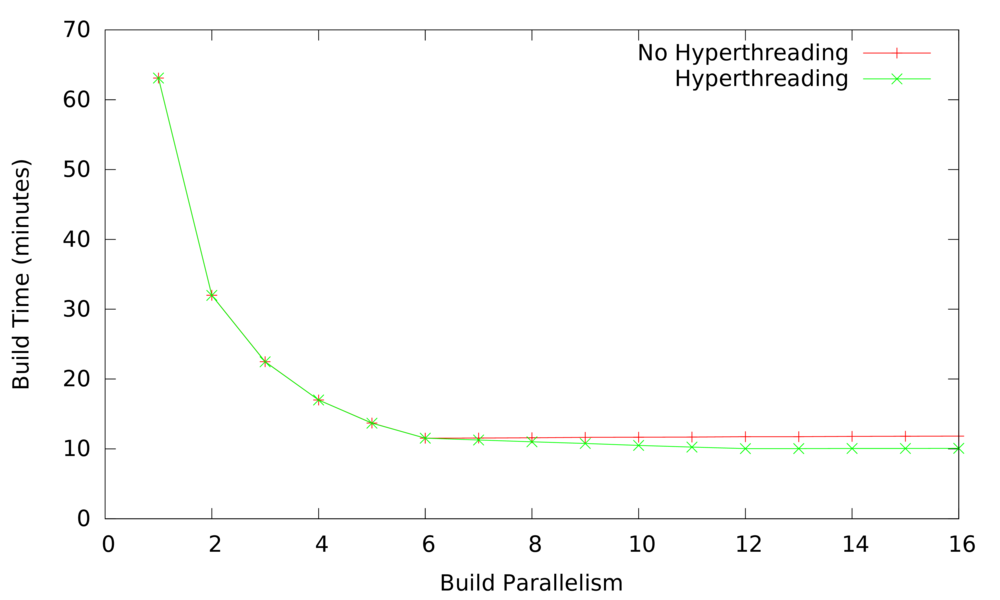
What can we take away from this graph? The main conclusion is that hyperthreading wins handily, reducing the best-case build time from 11.75 minutes to 10.04 minutes: an improvement of 1 minute and 42 seconds. Also, I had been worried that simply enabling HT would be detrimental since Linux would sometimes schedule two threads on the same real core when a different core was idle. The graph shows that either this happens only rarely or else it doesn’t hurt much when it happens. Overloading the system (forking more compilers than there are processors) hurts performance by just a very small amount. Of course, at some point the extra processes would use all RAM and performance would suffer significantly. Finally, the speedup is impressively close to linear until we start running more than one thread per core:
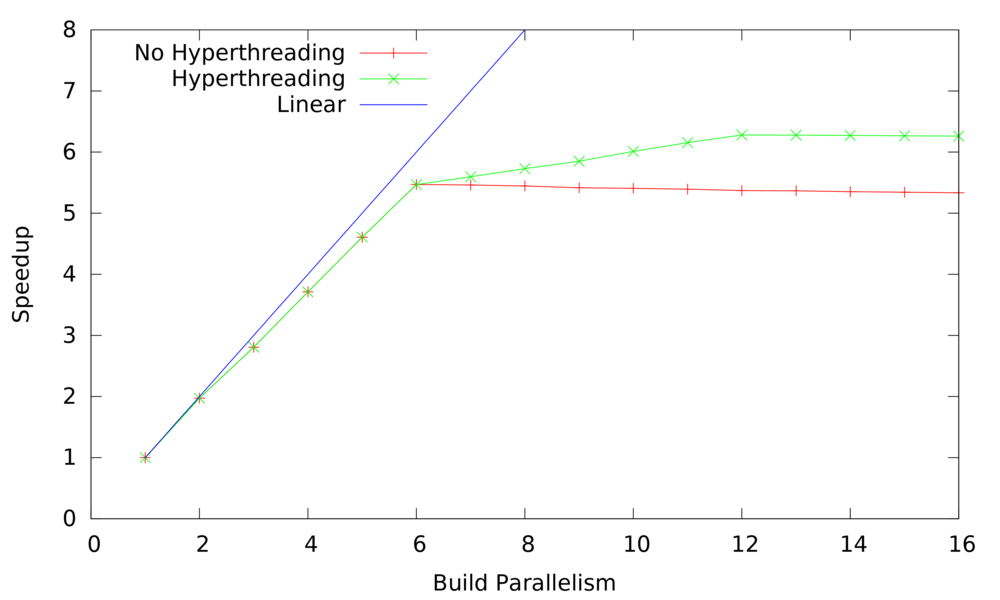
I don’t know how much of the nonlinearity comes from resource contention and how much comes from lack of available parallelism.
Here are the first and second graphs as PDF.
Looking at the bigger picture, a huge amount of variation is possible in the compiler, the software being compiled, and the hardware platform. I’d be interested to hear about more data points if people have them.
14 responses to “Compilation and Hyperthreading”
How about Debug build? Any estimation in the gain for debug build? Since it is more heavy it might be good to try as an example.
One data point: Using a late 2013 MBP running El Capitan with an i7-4850HQ (quad core with HT on) and 16GB ram, Apple LLVM 7.3 + make with 8 parallel jobs did the same compilation in ~7 minutes, a whole 3 minutes faster.
Given that your hardware is roughly the same generation, but has a desktop class CPU, perhaps the PCIe SSD is a bigger help than CPU.
My bad, I was only compiling LLVM, and not Clang + compiler-rt 🙂 The correct time is 14 minutes.
Quick test on work codebase (C++/Qt app) on an i7-6820HQ:
make -j8: 30.4s
make -j4: 37.8s
(tested twice each after warming caches, two runs were within 0.1s of each other)
This is not the point of the article but seeing the graphs all the way up to 100 or so would be interesting.
tobi my machine has only 16 GB of RAM and I think it would die well before 100.
Thanks glaebhoerl and Kavon!
suyog I’m out of time for benchmarking right now but might try debug builds later on. They won’t get as much speedup since linking gigantic debug binaries is slow and doesn’t parallelize.
sorry, how is this surprising? HT is interleaving, so wins when a thread has pipeline bubbles. compilation is largely pointer-following, so is mostly memory stalls…
Overclocking tips this question heavily against hyperthreading, whether a passively cooled Intel NUC, or four cores with behemoth cooling. Simply put, one can overclock further with hyperthreading off, more than erasing any faint cycle-for-cycle advantage to hyperthreading.
There’s now a ton of v1 E5-2670 cpus around for dirt cheap. You can build a 2-socket machine with 16 real cores (maybe 1.5x-2x the speed of the 6 core Haswell) for not much more than the Haswell machine costs, though with higher power bills. wholesaleinternet.com also has some cheap rentals of those machines, starting at $50/month for one with 32gb ram and a 240gb ssd. Unfortunately the configuration choices aren’t so flexible. I think these machines were retired from some huge computation farm at Facebook. There’s also a ton of them on ebay.
Oh yes, forgot to mention, in my own stuff (not very memory-heavy) I generally get about 20% speedup from HT. So a virtual core is worth about 60% of a real core.
Can’t comment any more on the ‘machine specs’ post linked above, so I’m going to highjack this one. I build a machine last week for a somewhat similar purpose you use it for (research on simulation systems, HPC). I chose a rack-mounted form factor; there are cheap rack chassis available for just a little bit more than the case you linked above, and I build a rack myself out of wood and rack rails sold for building audio equipment racks. Logistically I find a rack very convenient, especially since it’s a separate room and I run 50 feet DisplayPort cables to my monitors; although if I were concerned about the last tens of dollars I’d probably be cheaper to stack a bunch of tower cases on some cheap metal shelves.
Secondly I wonder why you didn’t go for a Xeon build – more specifically why you don’t use ECC. It was the hardest decision I made for my build, but I’m happy now that I went with a ‘server’ motherboard and an E5-1630. I didn’t want to risk (however small that risk) having some memory corruption throw one of my calculations off by essentially a random number, without having a way to even detect such issues.
I get the same conclusion from my dataset at http://stackoverflow.com/questions/2499070/gnu-make-should-the-number-of-jobs-equal-the-number-of-cpu-cores-in-a-system/18853310#18853310 . The CPU utilization goes from 100% on 1 core (assumed), down to 90% on 4 cores, and back up to 95% on 4 cores with HT turned on. If your linear line is accurate, then you are getting even better performance improvements with it on. Perhaps you can calculate the core utilizations to see how that fares?
Note also I saw a significant difference on multi-socket E5-26xx v4 when pinning with numactl. Results of large C compile were 75% of default when pinning, which makes sense.
Hi Peter, the core utilization was close to ideal — perhaps Ninja is better than make at keeping everyone busy.
Roel, for the very small cluster I run, it’s just easier to keep a few boxes under my desk than it is to deal with a rack, but I understand the benefits. Regarding the Xeons, I hadn’t seen the cheap boxes. I’m also an ECC fan but have not had any RAM troubles with these non-ECC boxes.