This continues a previous post.
We went through the lattice theory and introduction to dataflow analysis parts of SPA. I consider this extremely good and important material, but I’m afraid that the students looked pretty bored. It may be the case that this material is best approached by first looking at practical aspects and only later going into the theory.
One part of SPA that I’m not super happy with is the material about combining lattices (section 4.3). This is a useful and practical topic but the use cases aren’t really discussed. In class we went through some examples, for example this function that cannot be optimized by either constant propagation or dead code elimination alone, but can be optimized by their reduced product: conditional constant propagation. Which, as you can see, is implemented by both LLVM and GCC. Also, this example cannot be optimized by either sign analysis or parity analysis, but can be optimized using their reduced product.
We didn’t go into them, but I pointed the class to the foundational papers for dataflow analysis and abstract interpretation.
I gave an assignment to implement subtract and bitwise-and transfer functions for the interval abstract domain for signed 5-bit integers. The bitwidth is small so I can rapidly do exhausive testing of students’ code. Their subtract had to be correct and maximally precise — about half of the class accomplished this. Their bitwise-and had to be correct and more precise than always returning top, and about half of the class accomplished this as well (a maximally precise bitwise-and operator for intervals is not at all easy — try it!). Since not everyone got the code right, I had them fix bugs (if any) and resubmit their code for this week. I hope everyone will get it right this time! Also I will give prizes to students whose bitwise-and operator is on the Pareto frontier (out of all submitted solutions) for throughput vs precision and code size vs precision. Here are the results with the Pareto frontier in blue and the minimum and maximum precision in red (narrower intervals are better).
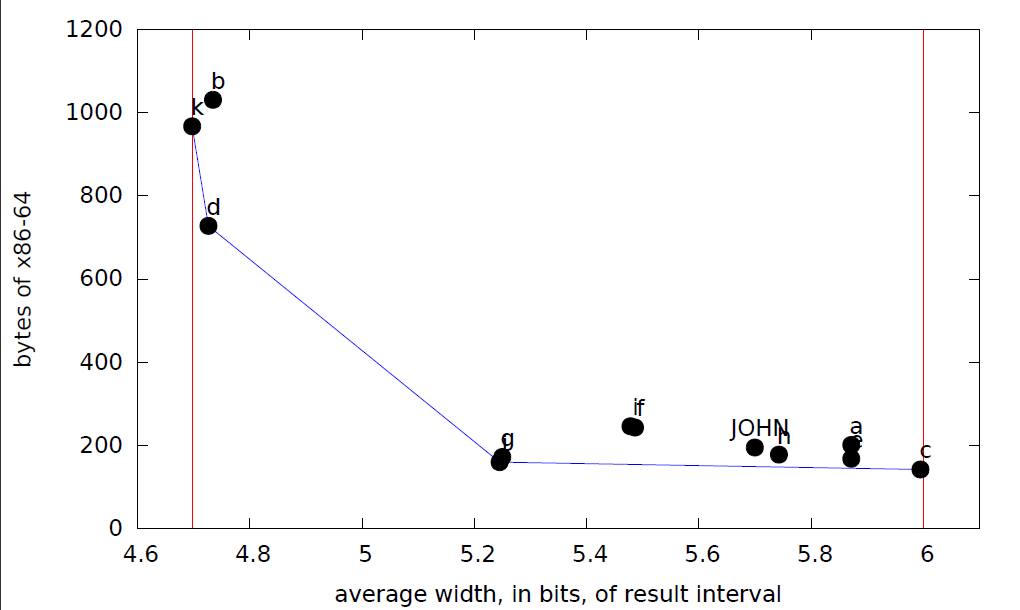
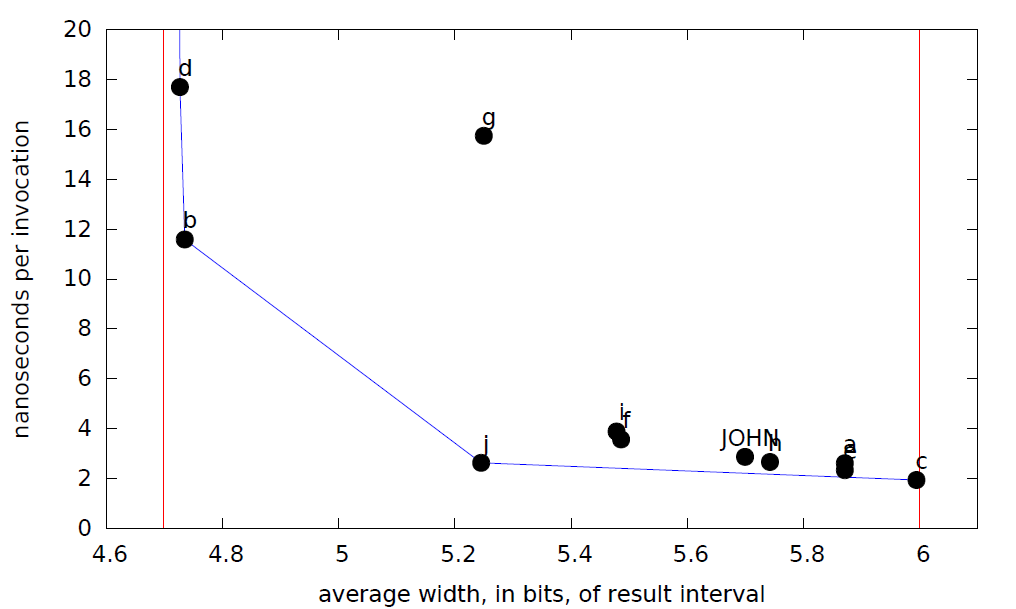
Impressively, student k implemented an optimally precise bitwise-and transfer function! Student c’s transfer function returned an answer other than top only for intervals of width 1. Mine (labeled JOHN) looked at the number of leading zeroes in both operands.
We looked at the LLVM implementation of the bitwise domain (“known bits”, they call it) which lives in ValueTracking.cpp. This analysis doesn’t have a real fixpoint computation, it rather simply walks up the dataflow graph in a recursive fashion, which is a bit confusing since it is a forward dataflow analysis that looks at nodes in the backward direction. The traversal stops at depth 6, and isn’t cached, so the code is really very easy to understand.
We started to look at how LLVM works, I went partway through some lecture notes by David Chisnall. We didn’t focus on the LLVM implementation yet, but rather looked at the design, with a bit of focus on SSA, which is worth spending some time on since it forms the foundation for most modern compilers. I had the students read the first couple of chapters of this drafty SSA book.
Something I’d appreciate feedback on is what (besides SSA) have been the major developments in ahead-of-time compiler technology over the last 25 years or so. Loop optimizations and vectorization have seen major advances of course, as have verified compilers. In this class I want to steer clear of PL-level innovations.
Finally, former Utah undergrad and current Googler Chad Brubaker visited the class and gave a guest lecture on UBSan in production Android: very cool stuff! Hopefully this motivated the class to care about using static analysis to remove integer overflow checks, since they will be doing assignments on that very topic in the future.
8 responses to “Advanced Compilers Weeks 3-5”
There recently appeared a nice book on instruction selection: http://www.springer.com/us/book/9783319340173
Any chance of linking to the assignment?
Dear John, My name is Lorenzo and I’m a developer in iOS field. I have been always enthusiast on understanding how things work under the hood, e.g. compiler, linker, assembler, machine code, llvm, etc. I really find your blog very interesting. There are a lot of concepts organized in a very good way. In order to be a better programmer (but also to satisfy my curiosity), I bought two main books (I haven’t started to read them yet) in order to acquire a deeper knowledge about these topics: Computer Systems: A Programmer’s Perspective and Computer Organization and Design: The Hardware Software Interface: ARM Edition. Do you think they are good enough in order to improve the skills I’m looking for? Do you suggest any other way to achieve my goal? Waiting for a feedback I thank you for your attention.
Andreas, thanks!
kme, here’s the string of assignments:
https://utah.instructure.com/courses/377698/assignments/3356986
https://utah.instructure.com/courses/377698/assignments/3376169
https://utah.instructure.com/courses/377698/assignments/3388871
Lorenzo, those books seem like great choices. I’ve taught courses based on the O’Hallaron and Bryant book many times. I guess the main thing is that you can’t just read the book, you need to do some of the programming exercises at the end of each chapter.
Here’s the assignment I just gave out yesterday, I’m excited about it:
https://utah.instructure.com/courses/377698/assignments/3396130
Also I pointed them to this little tester for ConstantRange transfer functions:
https://github.com/regehr/llvm-dataflow-research
Proving ConstantRange functions correct using a SAT solver would be more interesting, I think we’ll do that too.
5 bits is narrow enough to brute-force the lookup tables.
John Plevyak’s these uses Single Static Use (SSU) form, which restricts SSA so at to require at most one use per def. The idea is to have a PSI function that is analogous to PHI. In SSA, you would have a PHI to merge incoming values after a branch. SSU has this, but it also has a PSI to
“split” the value into two going down each side of the branch. It ends up turning the data flow into a nicely structure graph, and enables some nice forms of program specialization.
I’ve also always like Cliff Click’s sea of nodes IR, used in the HotSpot server compiler. His thesis demonstrates various ways of combining analyses over that IR, though I don’t recall if it’s the same kind of combination that you refer to in this blog post.
Peter, SSU sounds very similar to SSI:
http://publications.csail.mit.edu/lcs/pubs/pdf/MIT-LCS-TR-801.pdf
I don’t know sea of nodes but in general I am a huge fan of Cliff Click’s work.