[This piece is loosely a followup to this one.]
Background
Once a piece of software reaches a certain size, it is guaranteed to be loosely specified and not completely understood by any individual. It gets committed to many times per day by people who are only loosely aware of each others’ work. It has many dependencies including the compiler, operating system, and libraries, all of which are buggy in their own special ways, and all of which are updated from time to time. Moreover, it usually has to run atop several different platforms, each one individually quirky. Given the massive number of possibilities for flaky behavior, why should we expect our large piece of software to work as expected? One of the most important reasons is testing. That is, we routinely ensure that it works as intended in every important configuration and on every important platform, and when it doesn’t work we have smart people tracking down and fixing the issues.
Today we’re talking about testing LLVM. In some ways, a compiler makes a very friendly target for testing:
- The input format (source code) and output format (assembly code) are well-understood and have independent specifications.
- Many compilers have an intermediate representation (IR) that has its own documented semantics and can be dumped and parsed, making it easier (though not always easy) to test internals.
- It is often the case that a compiler is one of several independent implementations of a given specification, such as the C++ standard, enabling differential testing. Even when multiple implementations are unavailable, we can often test a compiler against itself by comparing the output of different backends or different optimization modes.
- Compilers are usually not networked, concurrent, or timing-dependent, and overall interact with the outside world only in very constrained ways. Moreover, compilers are generally intended to be deterministic.
- Compilers usually don’t run for very long, so they don’t have to worry too much about resource leaks or recovering gracefully from error conditions.
But in other ways, compilers are not so easy to test:
- Production compilers are supposed to be fast, so they are often written in an unsafe language and may skimp on assertions. They use caching and lazy evaluation when possible, adding complexity. Furthermore, splitting compiler functionality into lots of clean, independent little passes leads to slow compilers, so there tends to be some glomming together of unrelated or not-too-closely-related functionality, making it more difficult to understand, test, and maintain the resulting code.
- The invariants on compiler-internal data structures can be hellish and are often not documented completely.
- Some compiler algorithms are difficult, and it is almost never the case that a compiler implements a textbook algorithm exactly, but rather a close or distant relative of it.
- Compiler optimizations interact in difficult ways.
- Compilers for unsafe languages do not have lots of obligations when compiling undefined behaviors, placing the responsibility for avoiding UB outside of the compiler (and on the person creating test cases for the compiler). This complicates differential testing.
- The standards for compiler correctness are high since miscompilations are tough to debug and also they can quietly introduce security vulnerabilities in any code that they compile.
So, with that background out of the way, how is LLVM tested?
Unit Tests and Regression Tests
LLVM’s first line of defense against bugs is a collection of tests that get run when a developer builds the check target. All of these tests should pass before a developer commits a patch to LLVM (and of course many patches should include some new tests). I have a fairly fast desktop machine that runs 19,267 tests in 96 seconds. The number of tests that run depends on what auxiliary LLVM projects you have downloaded (compiler-rt, libcxx, etc.) and, to a lesser extent, on what other software gets autodetected on your machine (e.g. the OCaml bindings don’t get tested unless you have OCaml installed). These tests need to be fast so developers can run them often, as mentioned here. Additional tests get run by some alternate build targets such as check-all and check-clang.
Some of the unit/regression tests are at the API level, these use Google Test, a lightweight framework that provides C++ macros for hooking into the test framework. Here’s a test:
TEST_F(MatchSelectPatternTest, FMinConstantZero) {
parseAssembly(
"define float @test(float %a) {\n"
" %1 = fcmp ole float %a, 0.0\n"
" %A = select i1 %1, float %a, float 0.0\n"
" ret float %A\n"
"}\n");
// This shouldn't be matched, as %a could be -0.0.
expectPattern({SPF_UNKNOWN, SPNB_NA, false});
}
The first argument to the TEST_F macro indicates the name of the test case (a collection of tests) and the second names the actual test shown here. The parseAssembly() and expectPattern() methods respectively call into an LLVM API and then check that this had the expected result. This example is from ValueTrackingTest.cpp. Many tests can be put into a single file, keeping things fast by avoiding forks/execs.
The other infrastructure used by LLVM’s fast test suite is lit, the LLVM Integrated Tester. lit is shell-based: it executes commands found in a test case, and considers the test to have been successful if all of its sub-commands succeed.
Here’s a test case for lit (I grabbed the top of this file, which contains additional tests that don’t matter to us right now):
; RUN: opt < %s -instcombine -S | FileCheck %s
define i64 @test1(i64 %A, i32 %B) {
%tmp12 = zext i32 %B to i64
%tmp3 = shl i64 %tmp12, 32
%tmp5 = add i64 %tmp3, %A
%tmp6 = and i64 %tmp5, 123
ret i64 %tmp6
; CHECK-LABEL: @test1(
; CHECK-NEXT: and i64 %A, 123
; CHECK-NEXT: ret i64
}
This test case is making sure that InstCombine, the LLVM-level peephole optimization pass, is able to notice some useless instructions: the zext, shl, and add are not needed here. The CHECK-LABEL line looks for the line of optimized code that begins the function, the first CHECK-NEXT makes sure that the and instruction is on the next line, and the second CHECK-NEXT makes sure the ret instruction is on the line following the and (thanks Michael Kuperstein for correcting an earlier explanation of this test).
To run this test case, the file is interpreted three times. First, lit scans it looking for lines containing RUN: and executes each associated command. Second, the file is interpreted by opt, the standalone optimizer for LLVM IR; this happens because lit replaces the %s variable with the name of the file being processed. Since comments in textual LLVM IR are preceded by a semicolon, the lit directives are ignored by opt. The output of opt is piped to the FileCheck utility which parses the file yet again, looking for commands such as CHECK and CHECK-NEXT; these tell it to look for strings in its stdin, and to return a non-zero status code if any of the specified strings isn't found. (CHECK-LABEL is used to divide up a file into a collection of logically separate tests.)
An important part of a long-term testing campaign is using coverage tools to find parts of the code base that aren't being tested. Here's a recent LLVM coverage report based on running the unit/regression tests. This data is pretty interesting to poke around in. Let's take a quick look at coverage of InstCombine, which is generally very good. An interesting project for someone wanting to get started with LLVM would be to write and submit test cases that cover untested parts of InstCombine. For example, here's the first uncovered code (colored red) in InstCombineAndOrXor.cpp:
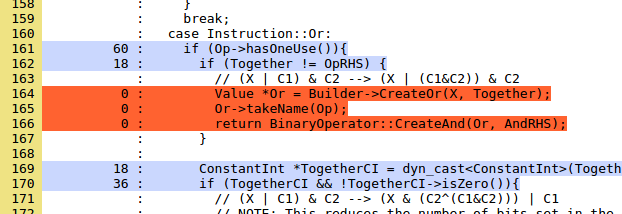
The comment tells us what the transformation is looking for, it should be fairly easy to target this code with a test case. Code that can't be covered is dead; some dead code wants to be removed, other code such as this example (from the same file) is a bug if it isn't dead:
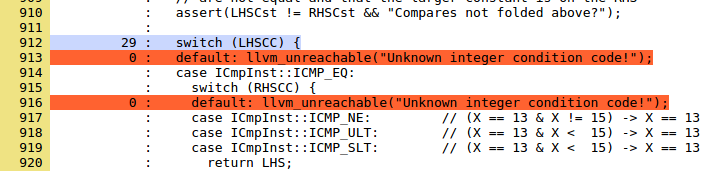
Trying to cover these lines is a good idea, but in that case you're trying to find bugs in LLVM, as opposed to trying to improve the test suite. It would probably be good to teach the coverage tool to not tell us about lines that are marked unreachable.
The LLVM Test Suite
In contrast with the regression/unit tests, which are part of the main LLVM repository and can be run quickly, the test suite is external and takes longer to run. It is not expected that developers will run these tests prior to committing; rather, these tests get run automatically and often, on the side, by LNT (see the next section). The LLVM test suite contains entire programs that are compiled and run; it isn't intended to look for specific optimizations, but rather to help ascertain the quality and correctness of the generated code overall.
For each benchmark, the test suite contains test inputs and their corresponding expected outputs. Some parts of the test suite are external, meaning that there is support for invoking the tests, but the tests themselves are not part of the test suite and must be downloaded separately, typically because the software being compiled is not free.
LNT
LNT (LLVM Nightly Test) doesn't contain any test cases; it is a tool for aggregating and analyzing test results, focusing on monitoring the quality of the compiler's generated code. It consists of local utilities for running tests and submitting results, and then there's a server side database and web frontend that makes it easy to look through results. The NTS (Nightly Test Suite) results are here.
BuildBot
The Linux/Windows BuiltBot and the Darwin one (I don't know why there are two) are used to make sure LLVM configures, builds, and passes its unit/regression tests on a wide variety of platforms and in a variety of configurations. The BuildBot has some blame support to help find problematic commits and will send mail to their authors.
Eclectic Testing Efforts
Some testing efforts originate outside of the core LLVM community and aren't as systematic in terms of which versions of LLVM get tested. These tests represent efforts by individuals who usually have some specific tool or technique to try out. For example, for a long time my group tested Clang+LLVM using Csmith and reported the resulting bugs. (See the high-level writeup.) Sam Liedes applied afl-fuzz to the Clang test suite. Zhendong Su and his group have been finding a very impressive number of bugs. Nuno Lopes has done some awesome formal-methods-based testing of optimization passes that he'll hopefully write about soon.
A testing effort that needs to be done is repeatedly generating a random (but valid) IR function, running a few randomly-chosen optimization passes on it, and then making sure the optimized function refines the original one (the desired relationship is refinement, rather than equivalence, because optimizations are free to make the domain of definedness of a function larger). This needs to be done in a way that is sensitive to LLVM-level undefined behavior. I've heard that something like this is being worked on, but don't have details.
Testing in the Wild
The final level of testing is, of course, carried out by LLVM's users, who occasionally run into crashes and miscompiles that have escaped other testing methods. I've often wanted to better understand the incidence of compiler bugs in the wild. For crashes this could be done by putting a bit of telemetry into the compiler, though few would use this if opt-in, and many would (legitimately) object if opt-out. Miscompiles in the wild are very hard to quantify. My hypothesis is that most miscompiles go unreported since reducing their triggers is so difficult. Rather, as people make pseudorandom code changes during debugging, they eventually work around the problem by luck and then promptly forget about it.
A big innovation would be to ship LLVM with a translation validation scheme that would optionally use an SMT solver to prove that the compiler's output refines its input. There are all sorts of challenges including undefined behavior and the fact that it's probably very difficult to scale translation validation up to the large functions that seem to be the ones that trigger miscompilations in practice.
Alternate Test Oracles
A "test oracle" is a way to decide whether a test passes or fails. Easy oracles include "compiler terminates with exit code 0" and "compiled benchmark produces the expected output." But these miss lots of interesting bugs, such as a use-after-free that doesn't happen to trigger a crash or an integer overflow (see page 7 of this paper for an example from GCC). Bug detectors like ASan, UBSan, and Valgrind can instrument a program with oracles derived from the C and C++ language standards, providing lots of useful bug-finding power. To run LLVM under Valgrind when executing it on its test suite, pass -DLLVM_LIT_ARGS="-v --vg" to CMake, but be warned that Valgrind will give some false positives that seem to be difficult to eliminate. To instrument LLVM using UBSan, pass -DLLVM_USE_SANITIZER=Undefined to CMake. This is all great but there's more work left to do since UBSan/ASan/MSan don't yet catch all undefined behaviors and also there are defined-but-buggy behaviors, such as the unsigned integer overflow in GCC mentioned above, that we'd like to flag when they are unintentional.
What Happens When a Test Fails?
A broken commit can cause test failure at any level. The offending commit is then either amended (if easy to fix) or backed out (if it turns out to be deeply flawed or otherwise undesirable in light of the new information supplied by failing tests). These things happen reasonably often, as they do in any project that is rapidly pushing changes into a big, complicated code base with many real-world users.
When a test fails in a way that is hard to fix right now, but that will get fixed eventually (for example when some new feature gets finished), the test can be marked XFAIL, or "expected failure." These are counted and reported separately by the testing tool and they do not count towards the test failures that must be fixed before a patch becomes acceptable.
Conclusions
Testing a large, portable, widely-used software system is hard; there are a lot of moving parts and a lot of ongoing work is needed if we want to prevent LLVM's users from being exposed to bugs. Of course there are other super-important things that have to happen to maintain high-quality code: good design, code reviews, tight semantics on the internal representation, static analysis, and periodic reworking of problematic areas.
2 responses to “Testing LLVM”
One minor inaccuracy: “This test doesn’t actually make sure that instructions have been removed, but rather ensures that the “and” instruction refers directly to the function argument %A.”
The use of CHECK-NEXT actually ensures these are the only instructions in the function. Any additional instructions would have to come either before the function name label (doesn’t make sense), after the ret (which is illegal IR), or between two lines which must be adjacent.
Thanks Michael! I’ll fix up the text when I get a minute.