Computer scientists tend to work by separating the essence of a problem from its environment, solving it in an abstract form, and then figuring out how to make the abstract solution work in the real world. For example, there is an enormous body of work on solving searching and sorting problems and in general it applies to finding and rearranging things regardless of whether they live in memory, on disk, or in a filing cabinet.
To paint a bit of a caricature, we have the real world where:
- all problems are engineering problems, and every engineering problem is distinct from the rest in small or large ways
- abstractions are leaky: machines fail, bits flip, packets drop, and bugs exist
- requirements are many-dimensional, diverse, and poorly specified
- systems often involve human beings who are notoriously hard to reason about
Overall, engineering problems are messy and we usually can’t prove anything about anything, any more than we could prove the correctness and optimality of a bridge or lawnmower.
On the other hand, in the abstract problem space, we’ve dropped every detail that we don’t wish to reason about but retained (ideally) all of the important characteristics of the problem. We’re now dealing with a model — sometimes a formal mathematical model, other times an executable model such as a kernel or simulation — of part or all of the problem. Models can be rigorously analyzed for efficiency, optimality, correctness, and whatever else. Furthermore, connections between problems that initially seem very different may become more apparent in the abstract form.
This process of lifting engineering challenges into abstract problems, solving them, and applying the results — I’ll call it the computer science research loop — is so integral to the DNA of computer science research that it is simply assumed; people have a hard time imagining any other way to work. Also, it has been incredibly successful, which is unsurprising since we inherited it from mathematics where it had been giving good results ever since some prehistoric person observed that you could talk about the number three without actually having three things in front of you.
Here’s the loop in its simplest form:
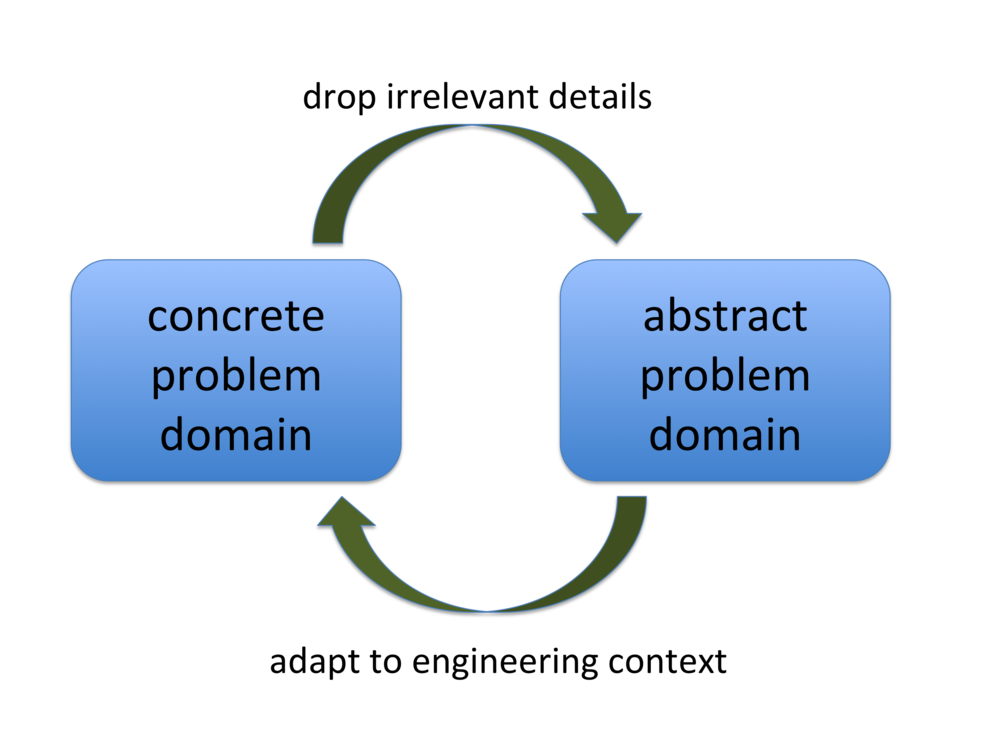
Here are some ways the research loop shows up in areas that I’m familiar with:
- In compilers we can develop a toy language that is much easier to compile but that (we argue) retains the essential features of real programming languages.
- In compilers we can compile a benchmark suite instead of real applications, arguing that our results will translate over into practice.
- In resource scheduling research it is typical to abstract away all details of the jobs being scheduled.
- In databases or operating systems we can create a transaction engine or OS kernel that supports only a tiny subset of the features provided by SQL Server or Linux, arguing that the advantages displayed by our simplified model would not disappear if we took the trouble to implement all the boring stuff.
In all cases the goal is to elide details that make our work harder, but without oversimplifying. This piece is about an avoidable but undesirable second-order effect: it is common for both edges of the computer science research loop to be weaker than they could be.
The concrete-to-abstract edge suffers when people working on the abstract side don’t have deep expertise in the concrete problems they’re trying to solve, and it also tends to weaken over time as the character of the problem drifts, causing assumptions on the abstract side to be invalidated. The abstract side has a kind of inertia: infrastructure builds up in code, formalisms, books and papers, and mental models. It requires significant time, energy, and risk-taking to throw away parts of the abstract infrastructure and create fresh pieces. Abstractions that are out of touch with real-world problems can linger, producing papers and PhD theses, for decades.
The abstract-to-concrete edge of the research loop is also problematic: solving real engineering problems, or interacting with the people whose jobs are to solve those problems, can be difficult and time-consuming. It is generally much easier to work purely on the abstract side, and in fact our field’s mathematical roots encourage this behavior. Abstract work is, of course, fine as long as someone else is doing the grungy part, but in many cases that never happens because the abstract side has drifted off to the side of the real problems, becoming more elaborate and complex over time as the easy problems get mined out, and in the end there’s no realistic prospect of applying it.
I believe these issues cause computer science research, overall, to be less interesting and impactful than it could be. I also believe that mitigating the problem isn’t that difficult and that doing so tends to make researchers’ careers a lot more fun and rewarding.
The solution is for researchers to engage with the world outside of their research bubble. Working on real-time scheduling? Then go find some drone software and help its authors or users avoid deadline misses, or else contribute scheduling code to Linux. Working on concurrency control in databases? Figure out a way to integrate the new scheme into MySQL or something, instead of waiting for them to read your paper. Working on finding bugs in software? Report the bugs to the people who maintain the code and watch their reactions. It is particularly important that students do these things, first because their intuitions often aren’t as well-developed and second because I’ve noticed that quite a few CS graduate students are quietly and privately wondering if their work is good for anything in the end. It turns out there’s a way to answer this question: engage with the people whose problems you are solving. As a bonus you’ll publish fewer papers.
It is not the case that that every piece of research should be applied research. Rather, good pure research usually stems from direct personal experience with problems on the engineering side of our world. It’s a bit of a subtle point: doing the grungy boots-on-ground work is how we build our intuitions about what kinds of solutions actually work vs. sounding good on paper. It is hard — though not impossible — to skip this step and still do great work.
Going a bit further, my experience is that much of the interesting action in research happens on the abstract-to-concrete edge of the CS research loop, even though this work is not glamorous or well-rewarded by program committees or grant panels. Even the old workhorses like sorting an array or implementing a key-value map became dramatically more interesting and complex in the context of a real machine, operating system, compiler, and workload.
Concretely, here are some things to look for that might indicate that a research community needs to tighten up its loop:
- few members of the community are plugged into the concrete problem domain, and are providing fresh insights from developments there
- few members of the community are moving abstract results into practice
- members of the community are mainly interested in impressing each other (or, equivalently, papers that demonstrate external impact are not highly valued)
- the community rewards complex solutions because they are innately interesting, as opposed to rewarding simple solutions because they have engineering merit
- years of results cluster around the same baseline or benchmark set, instead of continually moving the bar higher
In conclusion, the tension between mathematics and engineering is alive and well in our field. My belief is that more of us, perhaps even most of us, should be skilled in, and actively working in, both modes of thinking.
Also see this followup post.
11 responses to “Closing the Loop: The Importance of External Engagement in Computer Science Research”
John,
All true. I think one big tension here, and it’s a legitimate one, is between the desire in some sub-fields for statistical substance, and the desire for realism.
That is, the more realistic your (oh, let’s say our area is test generation) test generation/fuzzing is, the more you close the loop and report bugs, and use workflows that might be what a real bug-hunter would use, the fewer case studies/SUTs you will get. Moreover, they will be opportunistically selected: you’ll report on the three systems where your method was not a heroic effort to get working, not the two where it would have been interesting, but you are not a full-time test engineer. That’s a real bias if you want to know “how often does this method work?”
On the other hand, if you pull down randomly selected GitHub repos and do something much less realistic (and don’t report bugs, because you have no infrastructure for distinguishing real bugs from cases where you broke some assumption), you can produce both many more data points and there’s less bias in the selection. You can get an idea of whether the method works on the “typical” program.
Hi John
Re the last paragraph, I just read a short analysis on the needed math reqs for cybersecurity, if interested.
Byrd (2018) CYBERSECURITY: 1) WHAT MATH IS NECESSARY AND 2) DEVELOPING UBIQUITOUS CYBERSECURITY IN CURRENT COMPUTING PROGRAM https://dl.acm.org/citation.cfm?id=3199580
” report of both what specific math topics are needed for success in various aspects of cybersecurity and possible ways to integrate cybersecurity content into many or most of the courses of an academic computing program”
Maybe this suggests a new form of “impact factor”: abstract-to-concrete edge work that actually influences projects. I’ve no idea if granting panels would go for that, but it might be worth exploring. (I say this as someone who thinks the abstract-to-concrete edge is the most fun and interesting.)
So true, was the reason for me to study structural mechanics instead of cs. So I was able to solve one reallife problem during my diploma instead of concentrating on the abstract domain. Helped a lot even if my code looked really bad .
The New ABCs of Research: Achieving Breakthrough Collaborations
https://www.amazon.com/New-ABCs-Research-Breakthrough-Collaborations/dp/0198758839
After tenure, the push to increase your N-papers-per-year vs. spend the time to do “tech transfer” diminishes. One of the good things about tenure, in theory and (I think) in practice.
But going for impact makes dissemination of all but the most impressive work harder — John and I had a review for a paper (long ago) that said something like “isn’t this only useful for testing systems software?”
Which is a pretty weird question, and I think could still get asked today.
Alex, I agree this is a tricky tension!
But notice that I’m not arguing that all research needs to be engaged, but rather something more like “all researchers need to engage sometimes.”
Thanks Daniel!
Geoff, I agree.
Thanks Lionel. Are there some additional links to your own writings on this general subject that you might want to post here so people can find them more easily?
Alex I loved that review comment! Why would you bums only want to test systems software???
John: I know you’re not arguing against less-engaged research. I actually just mean that there is an annoying problem in that instance, and I would like to see inventive ways to get around it (if I had any, I’d propose them myself). The problem fundamentally is that real stuff requires engineering, and saying “I promise to do the engineering work for any random program” is not really workable. I don’t really think you can (yet) automate serious testing efforts, either.
Alex, I guess the real answer is that solid bugfinding work should almost always involve some manual reporting (no need for hero-level effort, but some) to get some ground-truth about relevance, but then we also need serious automated infrastructure for getting the statistics right with much less effort than it currently takes.
John,
Well, when you put it that way, I guess that is obviously the real answer. I’m still not sure what the right approach for the field is right now, though — I think experimental standards just aren’t quite calibrated.