Let’s take a second to recall this old joke:
A policeman sees a drunk man searching for something under a streetlight and asks what the drunk has lost. He says he lost his keys and they both look under the streetlight together. After a few minutes the policeman asks if he is sure he lost them here, and the drunk replies, no, and that he lost them in the park. The policeman asks why he is searching here, and the drunk replies, “this is where the light is.”
Using a generative fuzzer — which creates test cases from scratch, rather than mutating a collection of seed inputs — feels to me a lot like being the drunk guy in the joke: we’re looking for bugs that can be triggered by inputs that the generator is likely to generate, because we don’t have an obviously better option, besides doing some hard work in improving the generator. This problem has bothered me for a long time.
One way to improve the situation is swarm testing, which exploits coarse-grained configuration options in the fuzzer to reach diverse parts of the search space with higher probability. Swarm is a good idea in the sense that it costs almost nothing and seems to give good results, but it’s not remotely the end of the story. Today we’ll work on a different angle.
Let’s start out with a high-level view of the situation: we have a system under test, and its inputs come from a vast, high-dimensional space. If we confine ourselves to generating inputs up to N bits long, it is often the case that only a very small fraction of the 2N possibilities is useful. (Consider testing Microsoft Word by generating uniform random bit strings of 100 KB. Very nearly 0% of these would be enough like a Word document to serve as an effective test case.) This is the reason generative fuzzers exist: they avoid creating invalid inputs. (Of course mutation-based fuzzers work on a related principle, but this piece isn’t about them.)
Now we can ask: out of the space of inputs to the system under test, which parts of the space will trigger bugs? I would argue that unless we are doing some sort of focused testing, for example to evaluate the hypothesis “formulas containing trig functions often make Excel fall over,” we should assume that bugs are distributed uniformly. (And even if we are restricting our attention to formulas containing a trig function, we probably want to assume that this subset of Excel formulas contains uniformly distributed bugs.) It follows that a good generative fuzzer should explore the space of inputs with uniform probability, or at least it should be capable of doing this. Another way to state the desired property is: if the fuzzer is capable of producing X different test cases, each of them should be generated with probability 1/X. I don’t know that this property is optimal in any meaningful sense, but I do believe it to be a good and reasonable design goal for a generative fuzzer. Alas, a non-trivial generative fuzzer is very unlikely to have this property by accident.
Why is a generative fuzzer not going to naturally emit each of its X outputs with probability 1/X? This follows from how these tools are implemented: as decision trees. A generative fuzzer makes a series of decisions, each determined by consulting a PRNG, on the way to emitting an actual test case. In other words, this kind of tool starts at the root of a decision tree and walks to a randomly chosen leaf. Choices made near the root of the decision tree are effectively given more weight than choices made near the leaves, making it possible for some leaves to have arbitrarily low probabilities of being emitted by a decision tree. Let’s consider this very simple decision tree:
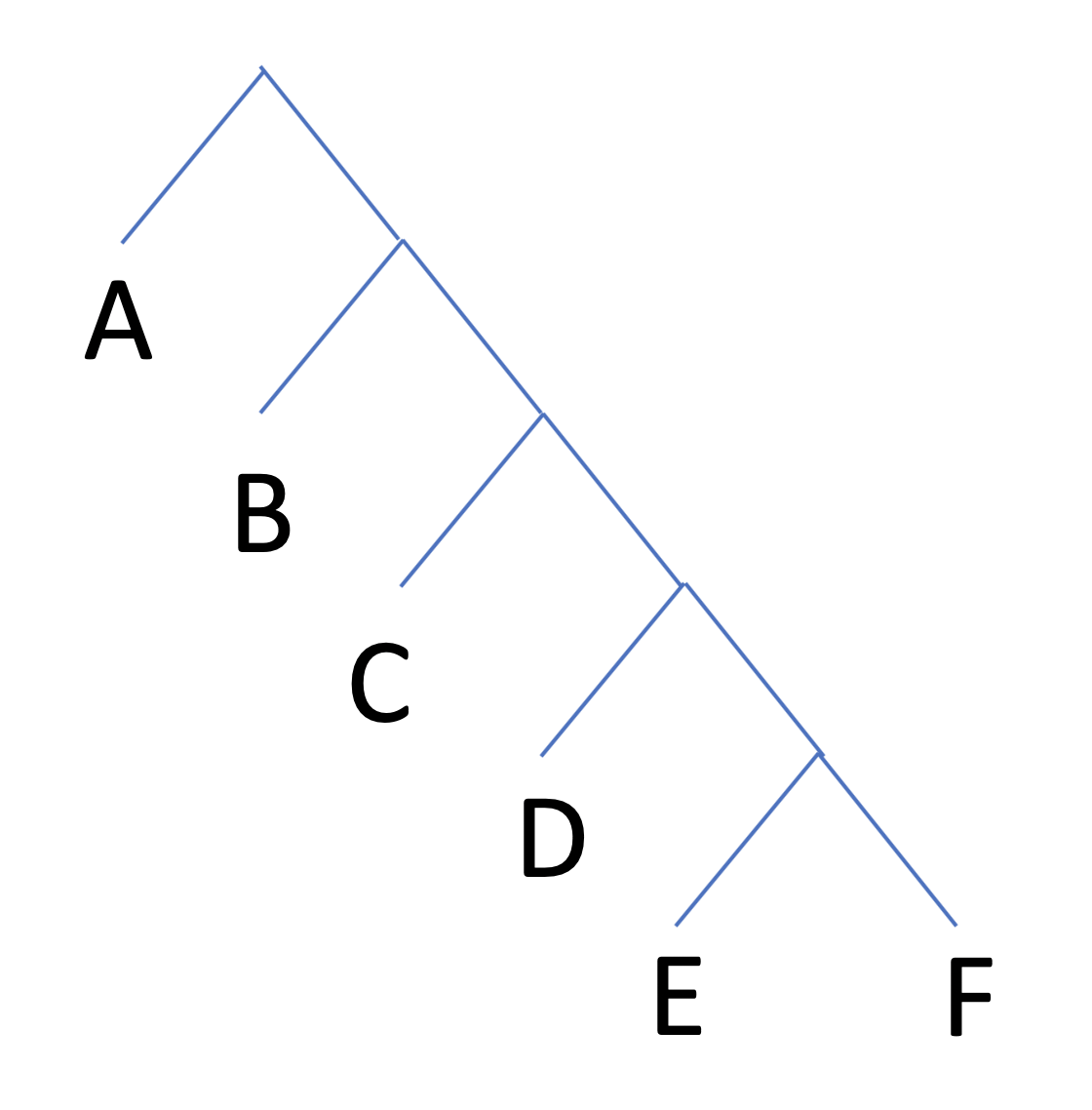
If we use it to generate output a bunch of times, we’ll end up getting outputs with percentages something like this:
A 49.979 B 25.0018 C 12.509 D 6.26272 E 3.1265 F 3.12106
If you are thinking to yourself “this example is highly contrived” then please consider how structurally similar it is to the core of a simple LLVM IR generator that I wrote, which has been used to find a number of optimizer bugs. (At the moment it only works as an enumerator, I ripped out its randomized mode because of the problems described in this post.)
So what can we do about this? How can we hack our decision tree to generate its leaves uniformly? A few solutions suggest themselves:
- Enumerate all leaves and then perform uniform sampling of the resulting list.
- Skew the decision tree’s probabilities so that they are biased towards larger subtrees.
- Structure the generator so that its decision tree is flattened, to stop this problem from happening in the first place.
Unfortunately, the first solution fails when the tree is too large to enumerate, the second fails when we don’t know subtree sizes, and the third presents software engineering difficulties. In Part 2 we’ll look at more sophisticated solutions. Meanwhile, if you’d like to play with a trivial generative fuzzer + leaf enumerator based on this decision tree, you can find a bit of code here.
Finally I want to briefly explain why generative fuzzers are structured as decision trees: it’s because they are effectively inverted parsers. In other words, while a parser takes lexical elements and builds them into a finished parse tree, a generative fuzzer — using the same grammar — starts at the root node and recursively walks down to the leaves, resulting in test cases that always parse successfully.
15 responses to “Helping Generative Fuzzers Avoid Looking Only Where the Light is Good, Part 1”
John, I started to say “swarm testing mitigates this specific problem” in that it has a 50% chance of lopping off one side of an unbalanced tree, in some runs, so ups the probability of taking the other, longer side. Of course, naively done, this is actually terrible, because a depth k leaf has 1-(0.5^k) chance of even being possible in each generation run.
BUT there is a better way, I think. In TSTL, the swarm configuration code first computes dependencies, then chooses to include/not include each grammar element (including leaves) independently. And then it applies a fixpoint where if X is in the configuration, you must have at least one way to produce each thing X consumes in the configuration. E.g., if you have:
:=
:=
Then if you flip the coin to include you will randomly add either or if neither is already present. This doesn’t do what you want, but if you ALSO had the rule that if X is in the set, and there are consumers of X, then at least one consumer must be present, you’d get something that sounds painful to analyze for probabilities, but seems like it ought to boost leaf probabilities quite a bit, by randomly building a path back to the top of the grammar from each leaf with 0.5 probability. And the fewer leaves you have under you, the fewer opportunities you have to be thus included, so it’s proportional to subtree size.
Ugh, it ate my grammar, of course, due to angle brackets.
The example, rewritten, is:
If you have:
EXPR := NUM
EXPR := STR
then if the coin for EXPR comes up heads, and those are the only ways to produce an EXPR, you randomly include one of STR or NUM, if they aren’t already in the configuration.
The new proposal would be that if you have:
STMT := ASSIGN(VAR, EXPR)
STMT := HALT
STMT := CATCHFIRE
STMT := IF (EXPR) STMT ELSE STMT ENDIF
EXPR := NUM
EXPR := STR
Then if you include STR, you are forced to include EXPR, and to include either ASSIGN or IF.
Works! Checked in as new default swarm behavior in TSTL.
Before this, I get these 30 second counts for your tree, without swarm:
22919 CHOICE: a
15747 CHOICE: b
10568 CHOICE: c
6958 CHOICE: d
4583 CHOICE: e
3103 CHOICE: f
Old swarm forcing dependencies doesn’t do much to change that, but noise, but with the approach where you force inclusion of at least one thing that depends on you, if anything does:
12030 CHOICE: a
9892 CHOICE: b
9264 CHOICE: c
7706 CHOICE: d
7711 CHOICE: e
10880 CHOICE: f
This all requires being able to at least approximate grammar dependencies, of course.
I like the better swarm, Alex!
Ok, on thinking, why is this NOT producing uniform probabilities?
Not exactly sure what you mean here, Alex, but typically only a small proportion of the random choices in a generator are directly controlled by flags, so we’re never going to get the actual property I want using this kind of mechanism.
I mean specifically why the dependence-aware parent adding swarm produces that weird A and F heavy distribution.
Yeah, I don’t know! Let me know if you figure it out.
https://github.com/agroce/tstl/blob/master/examples/lopsided_grammar/lopsided.tstl is the TSTL code.
10 seconds is plenty to see statistics. First, if you do nothing to help “F” and friends, you get what you got:
A 51.426%
B 25.437%
C 12.684%
D 6.203%
E 2.963%
F 1.288%
Using swarm with “parents” you get the weird, but much better:
A 28.117%
B 21.842%
C 15.926%
D 10.929%
E 9.509%
F 13.677%
Plain old swarm without any dependency analysis at all is terrible, actually:
A 70.054%
B 20.465%
C 6.523%
D 1.977%
E 0.695%
F 0.285%
That’s because if you include F but don’t include all of A-E, you don’t actually get F.
Finally, swarm with TSTL’s algorithm up until today, just “downward” dependencies (if X is in the config, make sure all the things X needs can be produced) gets:
A 53.544%
B 22.839%
C 11.569%
D 5.992%
E 3.042%
F 3.015%
Which is pretty similar to not using swarm, which I think makes sense. It helps some with the inclusion chain, because if you include the nonterminal side of a split in the tree, the dependency analysis includes the child so it isn’t impossible. Without that, A is the only thing with much chance of being possible, really (A only has a 50% shot, but tests that never produce anything are invisible).
Hey John,
My approach is different. Instead I map every element in the entire domain to a given integer index in such a way that I can select any element from the domain without enumerating it, or holding it in memory. Then, sampling uniformly is trivial. I have a library to help with this:
https://github.com/DavePearce/JModelGen
One of the challenges with this approach, of course, is dealing with constraints over your data types. For example, if generating random input programs, that every variable is used before being defined, etc. I don’t have a full answer for this, but there are sometimes tricks you can play.
Thanks David. I think your approach is more or less isomorphic to one of the ones I’m eyeing, which is to (approximately) compute subtree sizes analytically, and then use these to weight the generation probabilities.
For context-free grammars at least, shouldn’t it be possible to determine weights from the grammar itself, or is it a theoretically difficult task?
Hi Alexei, the context-free case has been solved, yes. The problem is that generative fuzzer (at least the ones I’ve written) tend to take context into account. One possible solution, however, is to see if a context-sensitive generator can be well-enough approximated by a CFG that this solves the problem well enough.