As part of some recent work we compiled 1,000,000 randomly generated C programs to x86 using a variety of versions of GCC and LLVM. Over the next few weeks I’ll post about some of the different things we learned from this experiment; today’s post is about code size. Each program was compiled at -O0, -O1, -O2, -Os, and -O3. We computed the code size for each compiled program using the size command. For each program that was compiled successfully by all compilers (about 10% of the programs crashed one or more compilers; more on that later) we considered the code size for a given compiler to be the smallest code size across all optimization options. The graph below shows the average code size for each compiler across all of the test cases. While nobody (besides us) is actually interested in compiling random C programs, the size does seem to be a least vaguely correlated with the optimizer’s ability to spot opportunities to propagate constants, eliminate dead code, destroy useless loops, etc.
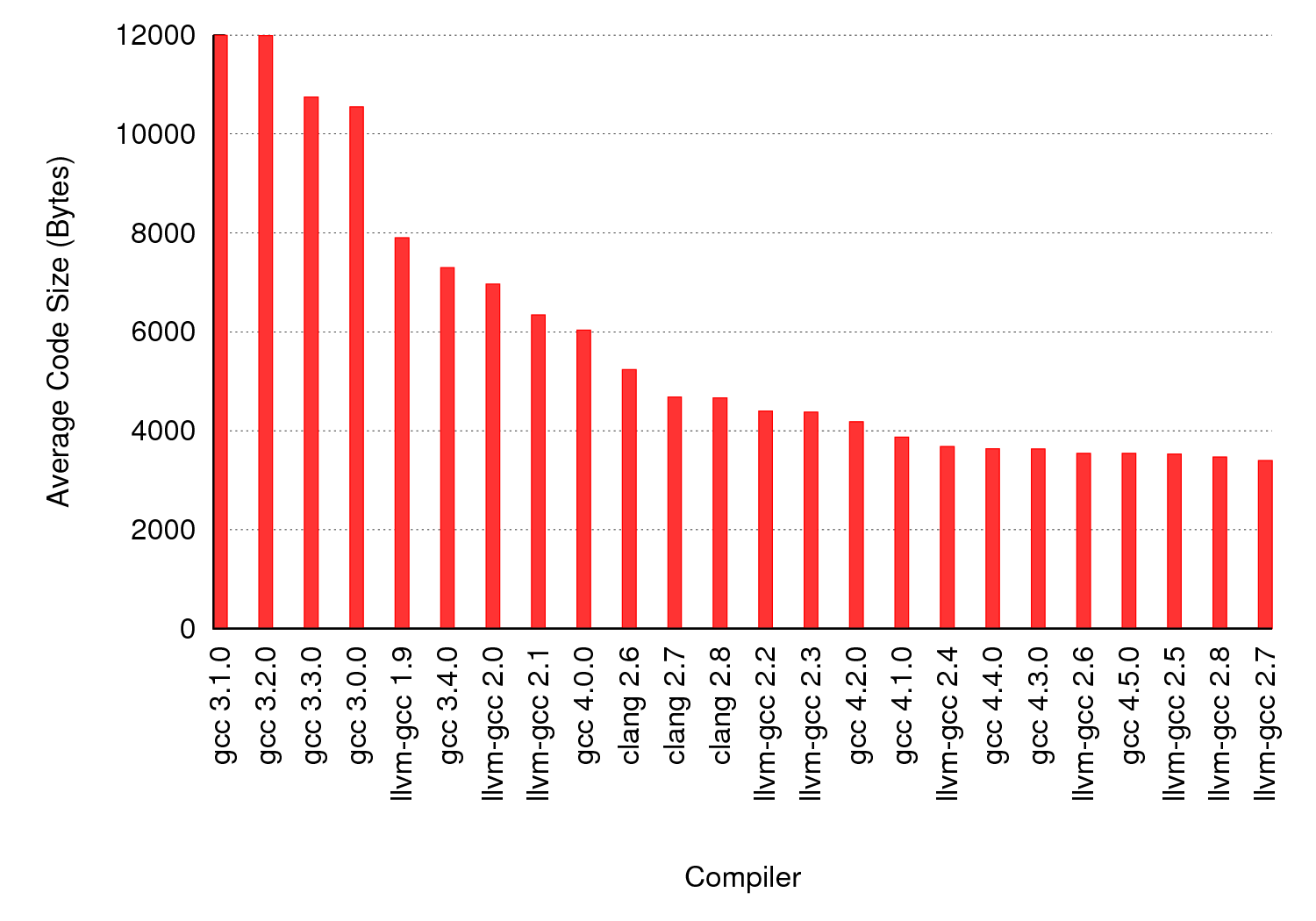
The main difference between real and random C code is that real programs are often fairly tight: the optimizer’s opportunities are mainly in low-level transformations like inlining, register allocation, common subexpression elimination, etc. On the other hand, random programs contain a huge amount of dead or useless code that the compiler can eliminate. A C compiler that does a good job optimizing random programs is not necessarily a better compiler, but it probably is one that can be relied upon to clean up junky code.
It’s interesting that LLVM-GCC generates smaller code than Clang. Of course, these compilers share middle- and back-ends. Most likely what is happening is that the GCC frontend is performing cleanups and random optimizations that have not yet been implemented in LLVM proper. Note that performing optimizations in the frontend is not necessarily desirable.
2 responses to “A Quick Look at Code Size”
How do you generate a random C program?
Hi Alejandro- An old version of our software and an old description of it can be found here:
http://www.cs.utah.edu/~eeide/emsoft08/