A basic service provided by most computer systems is isolation between different computations. Given reliable isolation we can safely run programs downloaded from the web, host competing companies’ sites on the same physical server, and perhaps even run your car’s navigation or entertainment software on the same processor that is used to control important system functions.
Other factors being equal, we’d like an isolation implementation to have a trusted computing base (TCB) that is as small as possible. For example, let’s look at the TCB for isolating Javascript programs from different sites when we browse the web using Firefox on a Linux box. It includes at least:
- pretty much the entire Firefox executable including all of the libraries it statically or dynamically links against (even unrelated code is in the TCB due to the lack of internal isolation in a C/C++ program)
- the Linux kernel including all kernel modules that are loaded
- GCC and G++
- some elements of the hardware platform (at least the processor, memory controller, memory modules, and any peripherals that use DMA)
A deliberate or accidental malfunction of any of these elements may subvert the isolation guarantee that Firefox would like to provide. This is a large TCB, though probably somewhat smaller than the corresponding TCB for a Windows machine. Microkernel-based systems potentially have a much smaller TCB, and a machine-verified microkernel like seL4 removes even the microkernel from the TCB. Even so, the seL4 TCB is still nontrivial, containing for example an optimizing compiler, the substantially complicated specification of the microkernel’s functionality, a model of the hardware including its MMU, and the hardware itself.
My student Lu Zhao’s PhD work is trying to answer the question: How small can we make the trusted 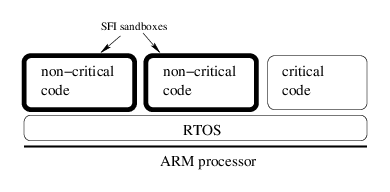
computing base for an isolation implementation? The target for this work is ARM-based microcontrollers that are large enough to perform multiple tasks, but way too small to run Linux (or any other OS that uses memory protection). Lu’s basic strategy is to implement software fault isolation (SFI). His tool rewrites an ARM executable in order to enforce two properties: memory safety and control flow integrity. We’re using a weak form of memory safety that forces all stores to go into a memory region dedicated to that task. Control flow integrity means that control never escapes from a pre-computed control flow graph. This boils down to rewriting the binary to put a dynamic check in front of every potentially dangerous operation. Using the excellent Diablo infrastructure, this was pretty easy to implement. I won’t go into the details but they can be found in a paper we just finished.
The trick to making Lu’s work have a small TCB was to remove the binary rewriter from the TCB by proving that its output has the desired properties. To do this, he needed to create mathematical descriptions of memory safety and control flow integrity, and also to borrow an existing mathematical description of the ARM ISA. Reusing the ARM model was ideal because it has been used by several previous projects and it is believed to be of very high quality. Automating the construction of a non-trivial, machine-checked proof is not so easy and Lu spent a lot of time engineering proof scripts. The saving grace here is that since we control where to add safety checks, the proof is in some sense an obvious one — the postcondition of the check provides exactly the property needed to establish the safety of the potentially-unsafe operation the comes after the check.
The TCB for Lu’s isolation solution contains the HOL4 theorem prover, his definitions of memory safety and control flow integrity (less than 60 lines of HOL), the model of the ARM ISA, and of course the ARM processor itself. All of these elements besides the processor are of quite manageable size. This work currently has two major drawbacks. First, the proofs are slow to construct and the automated proving part only succeeds for small executables. Second, overhead is far higher than it is for a state of the art sandboxing system such as Native Client. In principle the theorem proving infrastructure will be a powerful tool for optimizing sandboxed executables — but we haven’t gotten to that part of the work yet.
As far as we can tell, there’s not much more that can be removed from the TCB. Lu’s SFI implementation is the first one to do full formal verification of its guarantees for real executables. An important thing I learned from working with Lu on this project is that dealing with a mechanical theorem prover is a bit like having kids in the sense that you can’t approach it casually: you either go whole-hog or avoid it entirely. Perhaps in the future the theorem proving people will figure out how to make their tools accessible to dabblers like me.
11 responses to “Isolation with a Very Small TCB”
What is the limiting factor on the executable size? I would think that (assuming HOL4 can accept hits) proving code should be little more costly than a proof check. My thought is that it might be practical to have the re-write engine generate metadata that would guide the proof engine as to the most efficient way to generate the proof so that few if any blind alleys get followed.
Hi bcs, as I understand it the limitation comes from a large amount of repeated work done by the theorem prover — which is not very fast in the first place. We’re getting better at proof engineering (or Lu is, at least) and hopefully these limitations will go away soon.
If you’re not using the tools interactively at all, it would be interesting to see if we could use mlton to create a custom tool that would almost certainly run faster. (You are using Poly/ML at the moment I hope. The Moscow ML implementation is much slower, but it’s the only choice if you’re on Windows.)
Michael, we were using Moscow ML last I heard — hopefully Lu will chime in.
mlton does provide builds that work on windows. Admittedly, I haven’t tested them with much more than my tiny little code, so ymmv.
Hi Michael, we started with Moscow ML, but later I switched to Poly/ML, because it supports threads. I used multiple threads for checking which ARM instructions we could not get semantics for, but I do not use threads in our proof.
I heard of that mlton is the fastest ML, but I have never used it. Since you mentioned it, I guess HOL can run on it without any problem.
Hi bcs, we’re actually using something that is similar in concept to your suggestions, but completely different in implementation. We run an abstract interpretation that can generates intermediate theorems used by proving our program specification. The proof engine reuses those theorems. In addition, I also used cache for proven theorems.
The problem is the HOL’s rewriting process in proving theorems, because rewriting is costly in performance. For example, in order to prove an implication relation, I need to provide as many simplification theorems as possible in tactics, because I do not want to miss a successful case. However, if an implication relation does not hold, it takes seconds for HOL to raise an exception on proof failure. In our analysis, failure cases are common, and the time spent amounts to hours. A way to optimize this is to have a pre-proof analysis, which can tell if a proof will failure. If so, we do not have to run HOL’s proof at all. We just run a much less expensive conversion between input and output. However, such a pre-proof analysis is generally not possible without leveraging the power of SMT solvers.
There isn’t a HOL that runs on mlton because mlton doesn’t provide a REPL. There are also various other problems. It would be nice to have a big push so that we looked at it again.
Mlton doesn’t have multi-core concurrency either so if you’re doing good things with poly on multiple cores, mlton might not be a win after all. But, on a single core, mlton is much faster than poly…
Hi John/Lu,
Impressive work as always.
I don’t follow the claim in your paper that the OS is not in your TCB. Given that the OS could arbitrarily alter your process image in memory, incorrectly restore your registers on a context switch or any number of other undesirable behaviours, how can it be considered outside the TCB?
Hi Matthew, of course you are right. The intended interpretation of what we said is “the isolation guarantee is provided independently of the OS, as opposed to being provided by the OS.” If this isn’t clear then it’s our fault and we need to be more careful in the future.
Thanks for clarifying, John. I read the claim in the paper as the isolation guarantees remaining valid even in the presence of an incorrect and/or malicious OS. The term TCB is so overloaded today that it was probably my own misinterpretation. The OS-independence of the guarantees makes more sense, and I agree that it follows from your implementation.