Delta debugging is a technique for taking an input to a computer program that causes the program to display a certain behavior (such as crashing) and automatically creating a smaller input that triggers the same behavior. For complex programs that typically process large inputs (compilers, web browsers, etc.) delta debugging is an important part of the overall debugging workflow.
A key invariant in a delta debugger is that the current version of the input is always “interesting”—it triggers the bug or whatever. Delta speculatively transforms this input into a smaller input and then tests if this new input is still interesting. If so, it becomes the current input. Otherwise, it is discarded and a different transformation is tried. Termination occurs when no transformation can make the current input smaller. The greedy search looks something like this:
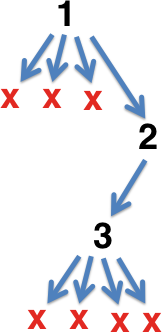
Here the original input (version 1) was transformed four times. Three of the resulting inputs failed to have the property of interest but the fourth was interesting, giving version 2. Version 2 was successfully transformed the first time, giving version 3 which, since it cannot be transformed any more, constitutes the delta debugger’s output.
While the original formulation of delta debugging uses only a single kind of transformation (removing a contiguous chunk of the input), we found that this didn’t produce nicely reduced C programs. My group’s tool, C-Reduce, is parameterized by a collection of pluggable transformations that, together, work better for this specific task.
In many cases, a run of a delta debugger takes only a few minutes, which is fast enough that we probably have no motivation to make it faster. On the other hand, we have found that reducing multi-megabyte C++ programs that trigger compiler bugs can be quite slow, on the order of a couple of days in some of the worst cases we’ve seen. Delta debugging is slow when the test for interestingness is slow and also when the greedy search fails to make rapid progress during its initial phases. Both of these tend to be the case for large C++ programs; rapid initial progress appears to be difficult due to the complex and dense dependency web in typical C++ code.
The other day I decided to parallelize C-Reduce for shared-memory machines. My first idea was to relax the delta debugging invariant so that each processor could have its own current version of the input. This requires a way to merge results so that processors can take advantage of each others’ progress. It would work something like this:
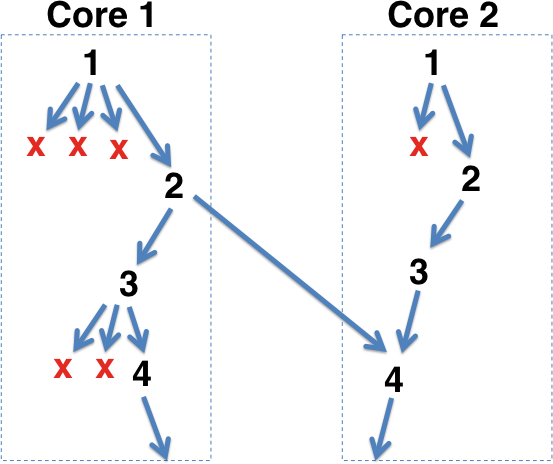
Here the code running on Core 2 has decided that instead of performing a regular C-Reduce transformation in version 3, it is rather going to merge version 3 with Core 1’s current version, which happens to be 2. Of course the result may not be interesting, but this diagram assumes that it is.
A problem is that existing utilities like “merge” are quite conservative; they aggressively signal conflicts. Also, it seems hard to know how often to merge. After a bit of experimentation I decided that this wasn’t the way to go. My next idea was to parallelize only the part of C-Reduce that performs line-based deletion of chunks of a file. If we rig C-Reduce so that instead of deleting lines it replaces them with blank lines, then merging becomes trivial. I think this was a reasonable idea but I stopped working on it after thinking of a simpler way.
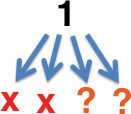
The strategy used by the current (development) version of C-Reduce maintains the delta debugging invariant that we always have a global best result. Parallelization happens by speculatively transforming the current input and then forking off subprocesses to test these inputs for interestingness. The strategy for speculation is to assume that no transformed input is interesting; I chose this heuristic because, in practice, transformations produce uninteresting results more often than not. In this illustration, two speculative processes have been forked but neither has completed:

As interestingness tests terminate, more are forked:
As soon as any transformation succeeds in producing an interesting result, all remaining speculative processes are killed off and a new batch is forked:
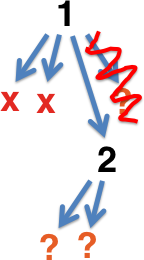
Since this kind of parallelization does not break the delta debugging invariant, not much of C-Reduce needed to be modified to support it. Although there are many improvements still to implement, performance seems decent. Here’s a graph showing reduction time vs. degree of parallelism on a Core i7-2600 with hyperthreading disabled for a 165 KB Csmith program that triggers this LLVM bug:
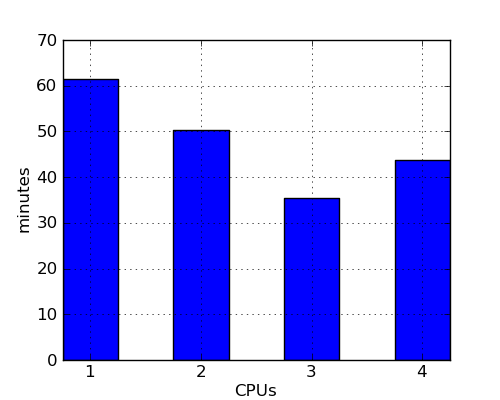
Why does performance get worse when C-Reduce uses all four cores? My guess is that some resource such as L3 cache or main memory bandwidth becomes over-committed at that point. It could also be the case that the extra speculation is simply not worth it.
Here’s what happens when we reduce a big C++ program that crashes a commercial compiler using an i7-2600 with hyperthreading turnred on:
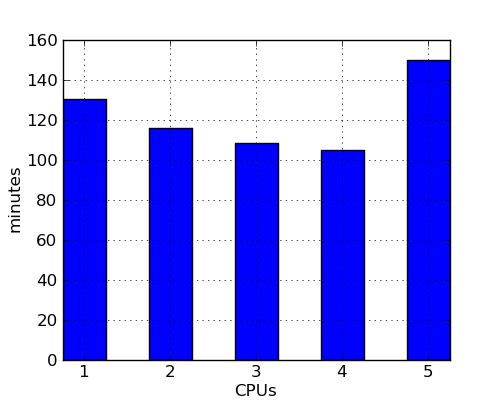
When the degree of parallelism exceeds five, performance falls even more off a cliff. For example, when C-Reduce tries to use six CPUs the reduction takes more than seven hours. This graph seems to tell the same story as the previous one: parallelism can help but some resource saturates well before all (virtual) processors are used.
I don’t yet know how C-Reduce will perform on a serious machine, but we have some new 32-core boxes that we’ll experiment with as we get time.
Perhaps my favorite thing about this little experiment with parallelization is that it leverages the purely functional nature of C-Reduce’s API for pluggable transformations. Previous versions of this API had been stateful, which would have made it hard to deal with speculation failures. I’m not particularly a fan of functional programming languages, but it’s pretty obvious that a functional programming style is one of the keys to making parallel programming work.
I decided to write this up since as far as I know, nobody has written a parallelized test case reducer before.
15 responses to “Parallelizing Delta Debugging”
I wonder why you considered the ‘merge’ approach first? The master-slave pattern is so easy and can even be extended to whole network of computers. Why would you need shared memory? Copy the reduced code variant over the network and let the interestingness-check run.
Hi qznc, the master/slave style of parallelism (in this case) has a fair amount of inherently sequential code, limiting the possible speedup. Independent delta instances that share results through merging have no such bottleneck.
Two things you might want to look into for your performance elbows:
– Are you running out of RAM?
– Particularly if it’s not an SSD drive, is the read/write queue length getting excessively long?
IIRC, back when we were tuning our parallel build performance at MSFT, those two factors were the ones that had to be monitored to avoid slowdowns.
Hi Lars, thanks for the suggestions.
These machines have 16 GB and I did not get the sense that they were anywhere near running out. Of course I should check more carefully.
Regarding disk, I believe (or at least hope) that not much data is actually hitting a platter. C-Reduce creates a temporary directory for each interestingness test and then deletes it after the test finishes. As long as Linux is bright enough to avoid flushing the dirty blocks for a few seconds, all is good. My /tmp is ext4 right now, I should run it out of a ramdisk and see if that helps.
This sounds a lot like what I’d do but just a tad more conservative, which might be reasonable depending on a few things. For example: how many reductions options are typicality available from any given step? what is the relative cost of the reduce steps vs the interestingness test? If the answers are “lots” and “high”, I can see why you take this approach. If not (i.e. “fewer” and “low”), what happen (or do you think would happen) if you always ran all of the reduces to completion on everything interesting and stuffed all the results in a priority queue?
As for distribute-ability, that should be easy if you have a large/fast enough network share. (OTOG, implementing it without to much re-writing might not be so easy.)
Hi bcs, the cost of the interestingness test is the major bottleneck in the slowest reductions, which are the ones I most want to speed up. They are not a bottleneck for quick reductions, which are probably not sped up at all by parallel execution (I haven’t even checked this).
Typically there are many possible ways (e.g. thousands) to reduce any given partially-reduced program, so the fanout of the search space is pretty gigantic.
A cluster C-Reduce would be fun to try but, as you say, would entail a fair amount of work.
So in other words, generating all the possible reduced files from a given input (that has already been proven to be interesting) isn’t a large cost. It’s then going and checking them that’s prohibitive.
I guess on a single system, you might run into disk cache pressure (or even disk space pressure if you are budget constrained). OTOH once you go to a cluster, the single disk throughput rates are on the same order as GigE NIC so reading from disk shouldn’t be that major a problem, particularly with a little pre-fetching thrown in.
I have written a parallelized version of Wilkerson’s delta script in C++ and run it in a cluster.
With the testcases I was handling, the common cause of slow deltas was long stretches where none of the trials were “interesting”. My system would build up the next ‘n’ test cases delta would try if all the ones before it returned “not interesting”.
The rest of the system sounds the same; if a worker returns “not interesting” prepare another test case and keep the workers busy, and if a worker returns “interesting” throw the currently-running batch away and start producing a new set. I made no attempt to try to merge multiple successful results from two workers.
Nick, that’s great to hear. Can you make it available, I wonder? Or, if not, I’d be interested to see some performance numbers.
I wonder if the following would be a useful way to do it:
Have N workers, and a globally tracked smallest test case
Each worker loops on the following task:
1. Take the current global test case.
2. Try a random reduction on it.
3. If the result of the random reduction is interesting, replace the current global best case if and only if the result is smaller than it (this might have changed in the meantime). You can do this with a compare and set.
Possible optimisation:
4. If we’ve failed to improve the result N times in a row (either because we produced uninteresting results or because someone else beat us to a more interesting one), shut down this worker.
You will end up with more duplicated work, but the result should hopefully be less contended and parallelize better because there’s no sequential relationship between the workers – each worker does its thing entirely independent of the results of the others, except that sometimes the others will give it a new test case to work off.
Additionally, with the optimisation in step 4, when you’re losing at parallelism because workers are stomping on each others’ work it should automatically scale back to a less parallel form.
Might be a stupid idea (I’m quite rusty at non-trivial parallel system design), but just a thought.
On further thought, it really is a stupid idea – it neglects how long the interestingness test can be. You might however get some benefit if you modified it so that you can signal “shut down and start again if the current test case you’re working on is longer than the current best option”.
Hi David, I don’t think your idea is stupid at all. If I wanted to scale C-Reduce up to a cluster, that’s how I would do it. But there are a couple of tricky things.
First. the reduction operations are designed to iterate sequentially through a test case. It would take a bit of work to make them random-access.
The second problem is trickier. The transformations are setup in a specific order so that earlier transformations are those that are likely to make a test case much smaller, with cleanup transformations being scheduled later on. We’d need to avoid randomly choosing lots of cleanup transformations early, while also not biasing the choices of transformation so much that work as duplicated. I’m sure this could be solved but it seems like there might be a lot of tuning to do.
The implementation is tied to a cluster system that doesn’t have a public implementation. That part is described here: http://google-engtools.blogspot.com/2011/09/build-in-cloud-distributing-build-steps.html and my delta trials were formulated as “build actions”, and ran with caching disabled. I’m not sure that’s the design I would choose if I were writing it again.
As for the part that produces files for each trial, it’s nothing you don’t already have in delta.pl. It really is a direct port of the perl code to C++.
I never took any performance measurements, I just started using it for new delta runs. At some point I stopped needing to run delta all the time and let the code bitrot. Anecdotally, my delta runs stopped being multi-day (up to 2 weeks) and turned into overnight runs.
regehr: Both those problems sound surmountable, though they do make the it more work:
Problem 1: If test case generation is fast enough compared to the delta debugging step, which it sounds like it is, you could just use a stream selection algorithm here. (Easy one: Generate a random integer for each element of the stream. Select the one with the smallest value)
Problem 2: You should be able to solve it by having the choice of transformation being adaptive based on what’s been proven to work.
Here’s one way it could work:
If we have N classes of test case for each of them we keep track of how many times we’ve run the test case and how many of those resulted in interesting behaviour (This would be local to the worker process). You could also cap this to only counting the most recent results perhaps. You could also start it off with some sensible prior probabilities
This gives us an estimate of the probability of the test case producing useful results. At any given point we choose a class with probability proportional to how likely it is to give a useful result, then randomly choose within this class.
The result should be that while it is useful to do so the test cases are pretty uniformly distributed across the different classes, but classes which have stopped being useful will get increasingly less likely. This might even be a useful thing to do in a sequential form of the program (but probably not).
Combining the two solutions: Just run the stream selection in a way that maintains a selection for each category then run the solution to problem 2 to pick which category you want.
One bit of the puzzle I think would be interesting to explore is a self tuning heuristic (i.e. machine learning) for ordering the interestingness tests (for the case where generating all the reductions is practical) or the reductions steps (for where it’s not) or both (for where it’s cheap to generate reduced cases but there are to many to generate all).