Over the weekend we released a new version of C-Reduce, a tool for turning a large C/C++ program into a small one that still meets some criterion such as triggering a compiler bug. There are two major improvements since the last release about a year ago:
- We are now able to run “interestingness tests” in parallel. The typical result is that C-Reduce speeds up quite a bit if you give it 4 or 8 cores. The parallelization strategy is explained here, but the speedups are now better than those reported in that article.
- We’ve added more than 20 new passes for reducing specific features found in C/C++ (mainly C++) programs. For example, C-Reduce now tries to instantiate a template, collapse a level of the class hierarchy, etc. The result is that C-Reduce’s endgame is significantly stronger for nasty C++ programs.
There are also plenty of minor improvements; for example, we now compile against LLVM/Clang 3.3 instead of requiring a random development version. We’ve made sure that C-Reduce works on Cygwin (for sort of a crappy value of “works” — it’s really slow, we believe due to Cygwin overheads). C-Reduce now supports --slow and --sllooww command line options that typically make test cases a little bit smaller, but at a high cost in reduction time.
Originally, C-Reduce was aimed at reducing programs emitted by Csmith. This wasn’t that hard because these programs contain only a limited set of language features. Over the last year or two the focus has been more on reducing C/C++ code found in the wild. This graph summarizes our current results for 15 compilation units from open source C/C++ programs, each of which causes some compiler to crash:
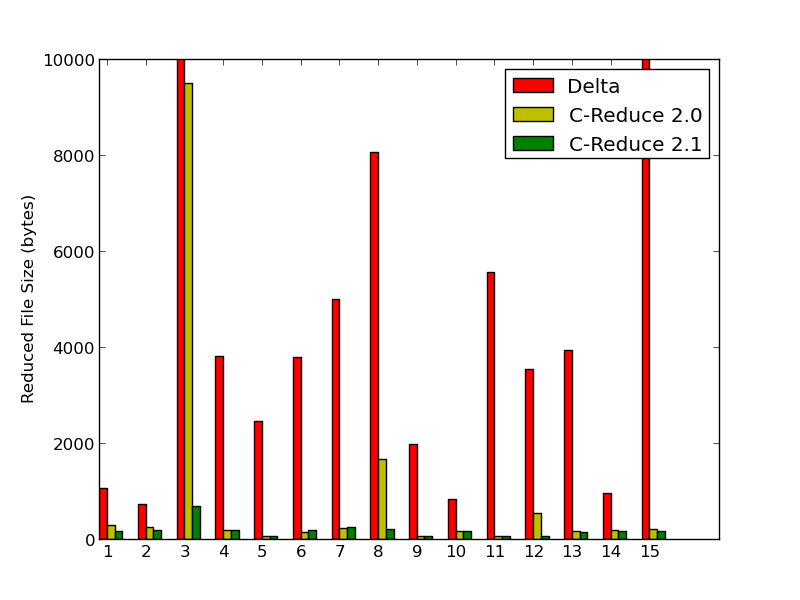
Whereas programs 8 and 12 stumped C-Reduce 2.0, the new version is able to produce fully reduced test cases. Program 3 could probably be improved a bit more (not all compiler bugs can be triggered by a very small test case, but most can). Programs 6 and 7 show a minor regression where the older C-Reduce was able to take some code out of an enclosing for loop and the new one is for some reason not able to do the same thing. Here Delta is being run twice at level 0, twice at level 1, twice at level 2, and then finally twice at level 10. My sense is that running it more times or at other levels would not improve the results much.
If you ever report bugs in C/C++ compilers, please give this tool a try.
6 responses to “C-Reduce 2.1”
Can it (or will it at some point) run on a cluster?
Does it still kill off potentially-interesting-and-possibly-smaller-but-not-done-yet-speculations?
Hi bcs, I don’t really have plans for using a cluster. The current strategy would probably scale up to a big NUMA, but some other parallelization strategy is probably called for on a cluster. And I’m not certain that this problem warrants that level of resources. In other words, if I had a big cluster at my disposal, I’d probably use each machine for fuzzing (clusterfuzz-style) and then when any process on a machine found an issue, switch that machine over to reduction — but let the rest of them keep fuzzing.
C-Reduce still follows the parallelization strategy outlined in that earlier blog post. It speculates that each transformation will not be interesting, until it has something running on each processor. As soon as an interesting variant is found, the speculative process groups are nuked.
“a tool for turning a large C/C++ program into a small one that still meets some criterion…”
…such as passing a unit test suite without emitting any compiler warnings.
I wonder if, in the process of preparing a software package for release, this could be used to “boil down the code” prior to compilation. The workflow might look like this:
1) Take a spec.
2) Write an acceptance test suite for it.
3) Write a relatively naive implementation of the spec.
4) Improve implementation until satisfied.
5) Run csmith to reduce implementation, stuff the reduced implementation into a subfolder.
6) Tarball up; there’s your source release.
7) Repeat from 1 for iterative improvements for future revisions.
Presumably, a reduced version of the code which still behaves (semantically) as desired would run faster and have a smaller resulting compiled binary size.
Hi Michael, I think what you’re getting at is that there’s an interesting analogy to make between a program reducer and a program optimizer. In fact, many of C-Reduce’s reduction transformations (copy propagation, function inlining, etc.) are also found in optimizing compilers.
The problem is that C-Reduce makes no attempt to be semantics-preserving. It will (effectively) try to break your code in subtle ways not detected by your test suite. If the acceptance test suite was complete, then this wouldn’t matter. But in practice this would be a very scary way to release code.
Also your suggestion is pretty close to this work which uses random mutation of software in order to fix bugs:
http://www.cs.virginia.edu/~weimer/p/weimer-gecco2009.pdf
There are some subsequent papers refining the ideas but this is a good place to start.
Hi, bcs. For whatever it’s worth, I’ve run C-Reduce on machines with up to 32 physical cores (and gobs of RAM). It’s nice.
Hm. Then I wonder if a semantic analysis diffing the result of C-Reduce against a straight compile could be used to identify weaknesses in my test suite.
The use cases I’m imagining are very small; they’d have to be, or the search space would rapidly grow insane.